|
|
看点:NVIDIA AI 部署宝典:数据中心必看,一并搞定算力、散热、功率难题。
2 N" a1 {, U: k6 p' n/ y$ } ! k3 Q+ K* M. |! h( n# H: p ! k3 Q+ K* M. |! h( n# H: p
& v( R4 _/ r' f$ m/ y/ V
2 H) k( U& C$ E$ ~; V. x; s) c/ g传统数据中心向人工智能(AI)转型已是大势所趋。
. ~; z* P- m+ g3 m2 W8 t! I一方面,从智能客服、智能安防、智能风控、智能运维到智能质检,愈加丰富的智能化应用致使存储需求呈现指数级增长,并对数据中心的算力提出新的挑战。
2 l* O8 \, F& [. C- A& `. g另一方面,AI 正打破传统数据中心的管理和运营模式,完成更为精准的系统调优、故障预判等任务,替代更多人力,减少能耗和资源浪费,更大程度释放生产力。3 T" N! I; X# o1 ^
作为 AI 时代的基础设施,AI 硬件正成为越来越多数据中心扩容建设的关键所在。尤其是能源、银行、保险、制造、电信、医疗等重度存储用户,急需加速 AI 的基础架构方案。: m" l/ `5 i/ O* Y# x, m: b( [; k6 e
当超强计算力成为数据中心的刚需,NVIDIA GPU 凭借强大的并行计算和浮点能力突破了深度学习的算力瓶颈,成为 AI 硬件的首选。/ {& y: y0 ~* j- M" F8 M
然而,对于许多传统数据中心而言,部署包含 AI 硬件的基础设施,需要耗费许多时间与人力。
$ Y$ }! d, h( |, r# X对此,NVIDIA 基于 GPU 软硬件生态系统,提供了一站式交付节点解决方案 DGX POD。
, T. m( Q* Q, ?2 C% ? }这一方案可以大大节省构建基础设施所花费的时间,帮助数据中心轻松快速进行 AI 部署,为扩展多 GPU 服务器节点提供更多支持。
, _, x, d. {5 Q: Y8 o本期的智能内参,我们推荐《NVIDIA DGX POD 数据中心参考设计》白皮书,从传统数据中心的 AI 转型之困着手,结合 DGX POD 的应用实例,解读 NVIDIA DGX POD 交付节点的核心亮点,为亟待快速转型 AI 的数据中心架构师,以及准备构建 AI 就绪型数据中心提供参考。如需查阅此白皮书《NVIDIA DGX POD 数据中心参考设计》,可直接点击左下方的“阅读原文”下载。
& ^* f7 Y X3 Q2 R8 m以下为智能内参整理呈现的干货:
: D2 p1 z, g, ~/ [4 I. `) ~. f2 O
数据中心 AI 转型遭遇困局( @0 d9 ]; }9 E9 c2 B
, X- Q- h; @3 J: U/ ~
, l" Y2 [- V/ W1 Q5 Z& m4 d& O
大数据、AI 与云计算等新兴技术卷起新的浪潮,在各类数据中心中形成连锁反应。海量数据处理任务涌入数据中心,面对人工智能应用的训练和推理,令传统的CPU 服务器难以招架。, z0 S# c+ D7 c6 t
深度学习算法属于计算密集型算法,与 NVIDIA GPU 计算架构十分契合。过去 CPU 需要花数十天完成的计算任务,通用 GPU 只用几小时就能完成,这大幅提升深度学习等并行处理数据方法的计算效率,使得以 GPU 为基础的设备日渐成为各大数据中心进行深度学习训练的首选。. K: f3 o8 ~" v, C
然而,即便部署了强大的硬件设备,也不意味着数据中心的 AI 转型计划就万事俱备了,还有一个关键问题摆在眼前——架构设计。
3 S' {+ e5 _- O数据中心需要考虑的因素远不止算力,还需兼顾网络、存储、电源、散热、管理和软件等方面问题。
" }1 V* T: u8 C" D. S6 O硬件组合不是简单粗暴的积木堆叠,并不是说计算节点越多,性能就会随之线性增长。其计算性能会受制于高速互联网络,一旦出现数据拥堵,整机系统的效率都可能被拖累。另外,过多计算硬件堆叠,可能导致功耗过大,不利于日后的运营。- i9 n8 E. a* R! y' V. _; U4 `
因此,数据中心必须思考如何打造了降本增效的最佳方式,将各种硬件资源协同组合,在稳定安全的状态下,以超低延迟和高带宽访问数据集。- l0 t u9 Y2 J0 F+ e7 d; T
这对于缺乏 AI 部署经验的传统数据中心而言,无疑是个不小的挑战。如果 DIY GPU 计算节点,不仅需要耗费人力和时间成本,还要考虑计算、存储、交换机等各种硬件设备的集成兼容问题。
& E6 @7 A; Z7 |' K) g' M对于这一痛点,NVIDIA 提供了一个颇有吸引力的解决方案。# H: |4 d, \3 D. @! ]4 J: z% {( S
它通过与领先的存储、网络交换技术提供商合作,提供一系列 DGX POD 数据中心交付节点设计参考架构,将 NVIDIA 长期积累的超大规模数据中心 AI 部署经验,转化为可复制方案,无论是大中小型数据中心,均可以直接参考使用。% P8 j6 t i: [" `2 B! e. t5 F/ e
7 N7 w( n; O4 u( H* {. X$ R# NNVIDIA AI 超级计算机构建经验转换9 y+ M3 |6 b- c" x9 O
7 k6 O: }7 A/ K" G; M
7 R" I7 e) W1 ^6 Y: V9 p
DGX POD 交付节点(Point of Delivery)是一种经优化的数据中心机架,包含多台 DGX-1 或 DGX-2 服务器、存储服务器和网络交换机等最佳实践。
! ]2 p8 j# O: C5 ]4 x 2 U9 b& }2 e' j! G. o& c4 q1 D 2 U9 b& }2 e' j! G. o& c4 q1 D
▲ DGX POD 参考架构正面图
W4 l. p, g/ {* `: ]7 h! z- h这是 NVIDIA 构建大量超大规模 GPU 加速计算节点的经验之集大成者。NVIDIA 曾建立了大型的 AI 数据中心,包含数千台领先的 DGX 服务器加速计算节点。9 |1 z( E, p. l- c/ S6 R
今年6月,NVIDIA 宣布推出全球速度排名第22位的超级计算机 DGX SuperPOD,为企业快速部署自动驾驶汽车项目,提供同等大小的超算无法匹敌的 AI 性能。
: U* V1 `& b8 H& \) J, g$ nSATURNV 亦是 NVIDIA 基于 DGX 系统构建的 AI 超级计算机,支持自动驾驶汽车、机器人、显卡、HPC 等多领域的 NVIDIA 内部 AI 研发。早在2016年推出之际,DGX SATURNV 就登上 Green 500 超算榜第一,被评为全球最经济高效的超算,整体运算速度位列第28位,是最快的 AI 超算。& {; B! Z. u4 _9 X
基于使用 SATURNV 所遵循的设计原则和架构,NVIDIA 在短短三周内就打造出一套基于 NVIDIA DGX-2 配置的全新系统 DGX SuperPOD。近期 NVIDIA 借助一套基于 DGX-2 的配置在 MLPerf 基准测试中创下六项 AI 性能记录。+ c1 y8 o+ L8 ]1 G
在将 DGX SATURAN 打造成所有企业都可复制的、经验证的设计过程中,NVIDIA 经过实地检验积累了丰富的经验,并将计算、网络、存储等多方面的最佳实践,集中于 NVIDIA DGX POD 的设计之中。: b7 |$ ^8 q% A% |
如今,包括 Arista、思科、DDN、Dell EMC、IBM Storage、Mellanox、NetApp 和 Pure Storage 等在内的业内数据中心领导者已围绕 DGX POD,推出了基于其各自特有技术的相关产品。" F7 Y3 d4 s3 E `3 i4 `
这些集成系统均为客户提供经过经验验证的可靠方法,这意味着,每个企业都能量身定制完全适配自身需求的 AI 超算中心。
: B& s) B+ N( r7 L( j例如,基于 DGX POD,NetApp 推出了 NetApp ONTAP AI 融合基础架构。其由 NVIDIA DGX-1 服务器、 NetApp 云互联存储系统提供支持,是 NVIDIA 和 NetApp 联合开发和验证的架构。0 |$ d% _4 B4 ^( F
借助这一架构,企业可以从小规模起步进行无缝扩展,智能管理跨边缘、核心和云以及反向数据传输的完整深度学习数据管道,简化 AI 部署。
" ^! E& S4 H5 h A2 B q3 e5 S围绕 NVIDIA DGX POD 参考架构和 NetApp ONTAP AI,英国剑桥咨询公司构建了一套专门的 AI 研究设施,用于训练一个能即刻准确识别各种音乐流派的 AI “狂热爱好者”。: L' P4 ?" U. P
借助参考框架,其 AI 项目所带来的对计算、存储、网络设施的需求均得到满足。经过在16台 NVIDIA GPU 上接受数百小时的音乐训练,这位特殊的音乐爱好者,在“听音识流派”的准确度上,甚至超越了人类和传统编程。3 F0 m8 A J6 F: }2 ^& Z. h) T
% h& e! m3 P0 X( J) N. L9 k# C0 }
AI 软件:调优 DGX 硬件,降低管理门槛
! [6 {0 h6 d3 O4 D/ C. O: L/ h3 a, z0 N
1 k4 y8 s, d& n8 ?: M除了设计优化的 DGX 服务器、存储服务器和网络交换机组合 ,DGX POD 上还运行一整套适配的 NVIDIA AI 软件堆栈,极大简化 DGX POD 的日常操作与维护,为大规模多用户 AI 软件开发团队提供高性能的深度学习训练环境。
8 c' y4 X6 w/ D ~+ R 8 H: H4 z* {5 J, c- h2 B 8 H: H4 z* {5 J, c- h2 B
▲ NVIDIA AI 软件堆栈 F4 u, h* v7 D0 D
NVIDIA AI 软件包括 DGX 操作系统(DGX OS)、集群管理和协调工具、工作负载调度器、来自 NVIDIA GPU Cloud (NGC) 容器注册表的和优化容器,可以为使用者提供优化的操作体验。/ r, A) R4 Z- N
DGX POD 管理软件可根据需要,自动创新安装 DGX OS。DGX OS 是 NVIDIA AI 软件堆栈的基础,基于优化版 Ubuntu Linux 操作系统构建,并专门针对 DGX 硬件进行调优,支持各种 NVIDIA 库和框架及 GPU 的容器进行时。
) R7 ~, i% F/ }4 `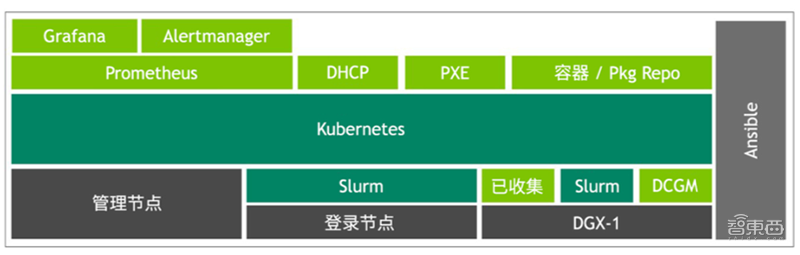 ) i6 l' N4 V7 H0 }% ~2 s ) i6 l' N4 V7 H0 }% ~2 s
▲ DGX POD 管理软件层! i3 i+ F" X& ^: m1 V8 ~4 _3 q8 X7 h
DGX POD 管理软件层由 Kubernete 容器协调框架上运行的各项服务组成,可通过网络(PXE)为动态主机配置协议(DHCP)和全自动 DGX OS 软件配置提供服务。+ D- \6 T, Y# H1 o7 j3 x# i
通过使用其简单的用户界面,管理员可在由 Kubernetes 和 Slurm 管理的域中移动 DGX 服务器。未来 Kubernetes 增强功能预计在纯 Kubernetes 环境中,支持所有 DGX POD 用例。; X7 x. v' e! l: I D' ~& |
DGX POD 上的 NVIDIA AI 软件可借助 Ansible 配置管理工具进行管理,白皮书中有提供其开源的软件管理堆栈和文档在 Github 上的链接。
% }3 b3 b' ]& ]智东西认为,DGX POD 一站式交付节点解决方案,不仅能加速数据中心的 AI 部署效率,同时也通过提供更强大的算力,大幅度提升数据的利用效率。
/ Z/ p) f3 e3 a# {6 z当前,很多数据中心刚刚踏入或计划踏入 AI 的大门,而当下主流的深度学习算法必须配备专业的 AI 基础设施。基于 NVIDIA DGX POD 的架构方案,对于快速构建大规模 AI 计算集群非常具有参考价值。随着此类基础架构逐渐普及,更多数据中心将得以消除设备与资本预算之间的鸿沟。
& p* q4 V. F w" r, O5 ?2 ?5 }7 Y这只是 NVIDIA 打造 AI 就绪型数据中心宏图的重要版面之一,利用 DGX-1、DGX-2 服务器和NVIDIA GPU 大规模计算架构的发展进步,NVIDIA 正将机器学习、深度学习和高性能计算(HPC)扩展到更多的数据中心,为金融、能源、制造、电信、医疗、科学计算等更多行业的生产力提升提供动力引擎。
& w8 S- K0 `" ]+ }如需查阅此白皮书《NVIDIA DGX POD 数据中心参考设计》,可直接点击左下方的“阅读原文”下载。) {0 I# `" H; h
4 P8 s+ D$ U6 H9 n( e- L' K) ~
% T2 b8 B l0 S0 W, B
来源:http://mp.weixin.qq.com/s?src=11×tamp=1564324204&ver=1756&signature=lzmOBny3VsKicsBbRilU-jCqaXPlfHO3NiPHxSA5ExQEflvku*zNzABRYJyH2rWKX7OAx1rw4BgY1r0zcj8uiuuI7R3fWMirVZVvIGuP3Oj7k7hAUZBuO0wn8Gimb5uD&new=1, ?( U4 i2 c3 c5 T R2 E$ z9 ]
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册

×
|
 /6
/6 
 |手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
|手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图

 发表于 2019-7-28 23:03:46
发表于 2019-7-28 23:03:46
