目次一、先容官网先容: [code]https://dev.mysql.com/doc/refman/5.7/en/explain-output.html https://dev.mysql.com/doc/refman/8.0/en/explain-output.html[/code]explain(实行计划),使用explain关键字可以模仿优化器实行sql查询语句,从而知道MySQL是怎样处理sql语句。 explain主要用于分析查询语句或表布局的性能瓶颈。 通过explain命令可以得到:
EXPLAIN 或者 DESC命令获取 MySQL 怎样实行 SELECT 语句的信息,包括在 SELECT 语句实行过程中表怎样连接和连接的顺序。 版本环境
基本语法 EXPLAIN 或 DESCRIBE语句的语法形式如下: [code]EXPLAIN SELECT select_options [/code]或者 [code]DESCRIBE SELECT select_options [/code]环境准备: [code]CREATE DATABASE testexplain CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci; [/code] [code]use testexplain; [/code] [code]CREATE TABLE L1(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) ); CREATE TABLE L2(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) ); CREATE TABLE L3(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) ); CREATE TABLE L4(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) ); [/code] [code]INSERT INTO L1(title) VALUES('test001'),('test002'),('test003'); INSERT INTO L2(title) VALUES('test004'),('test005'),('test006'); INSERT INTO L3(title) VALUES('test007'),('test008'),('test009'); INSERT INTO L4(title) VALUES('test010'),('test011'),('test012'); [/code]
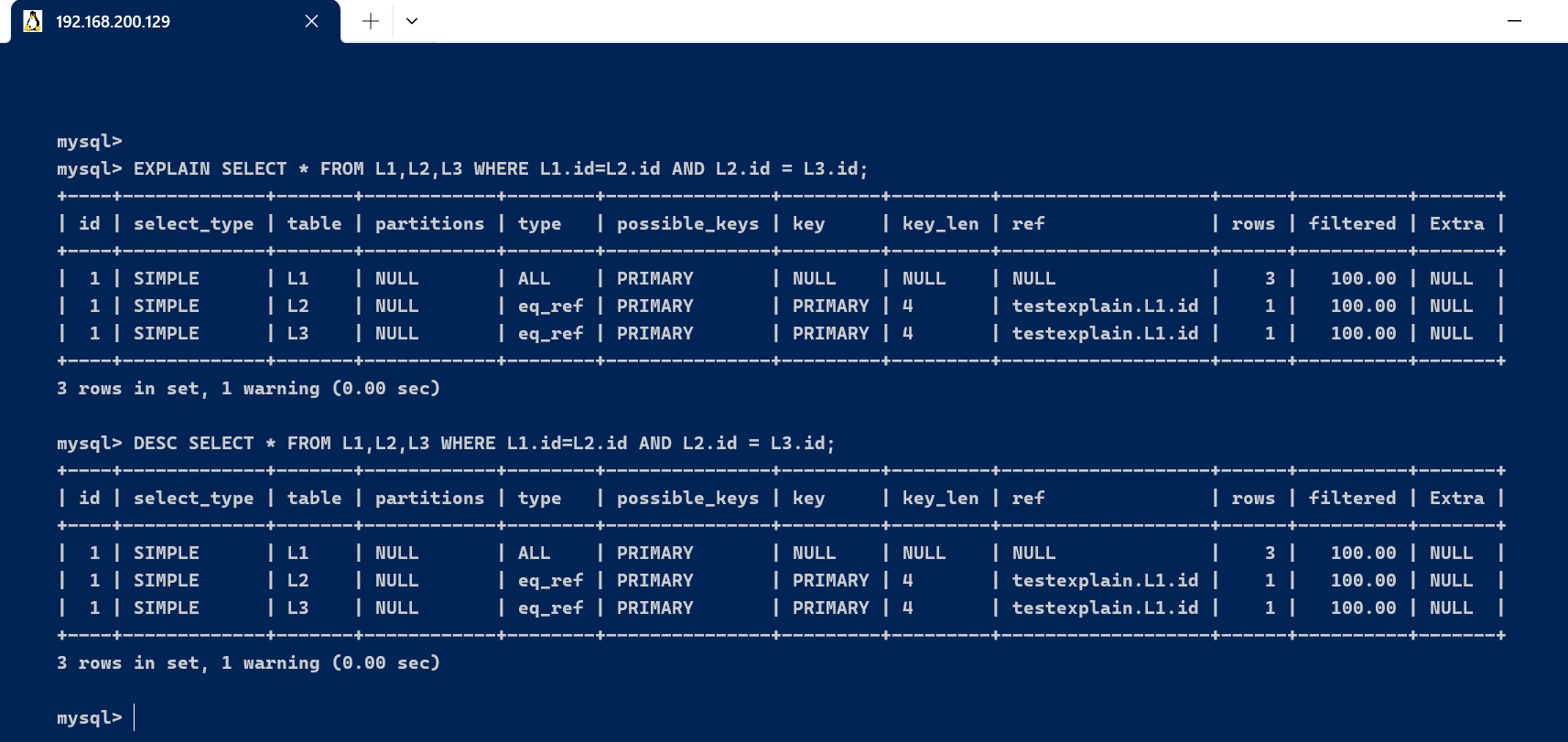
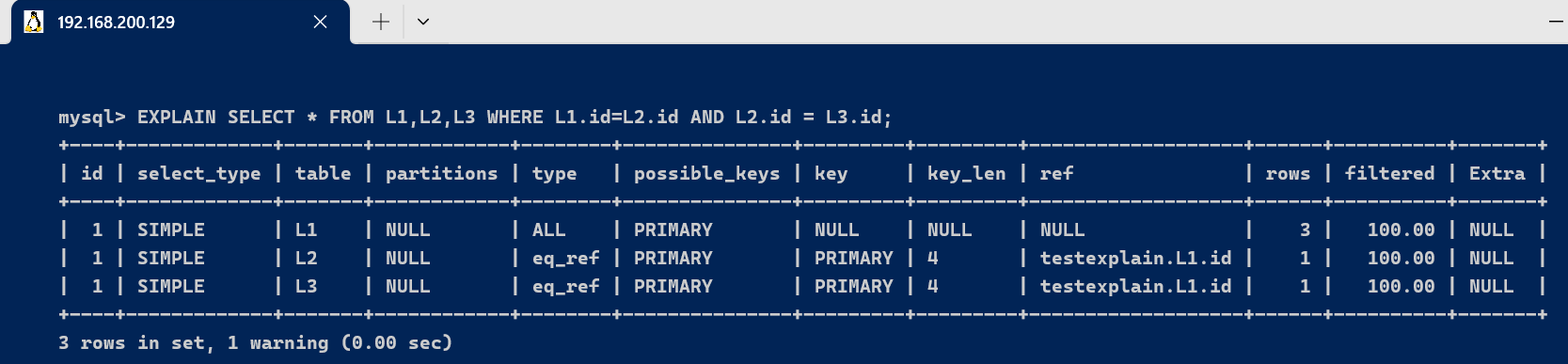
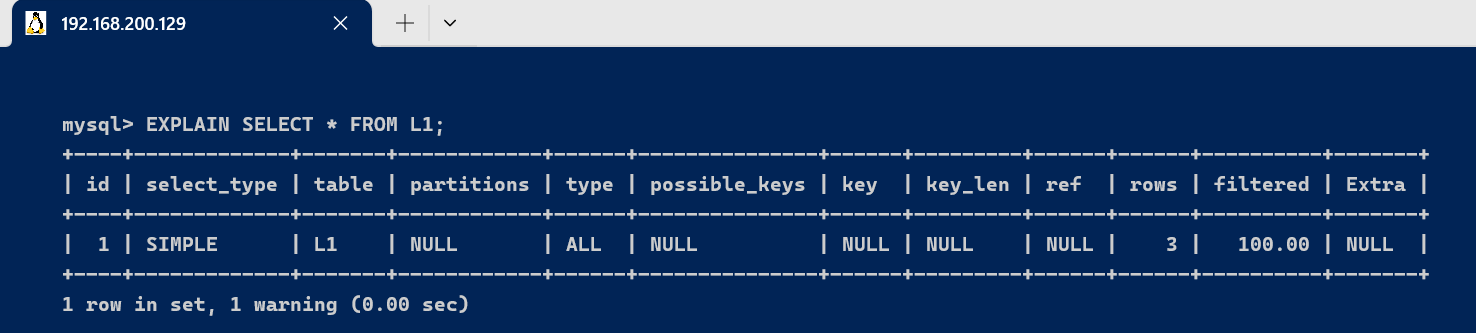
二、基本的使用explain使用:explain/desc+sql语句,通过实行explain可以得到sql语句实行的相关信息。 [code]EXPLAIN SELECT * FROM L1,L2,L3 WHERE L1.id=L2.id AND L2.id = L3.id; [/code] [code]DESC SELECT * FROM L1,L2,L3 WHERE L1.id=L2.id AND L2.id = L3.id; [/code]
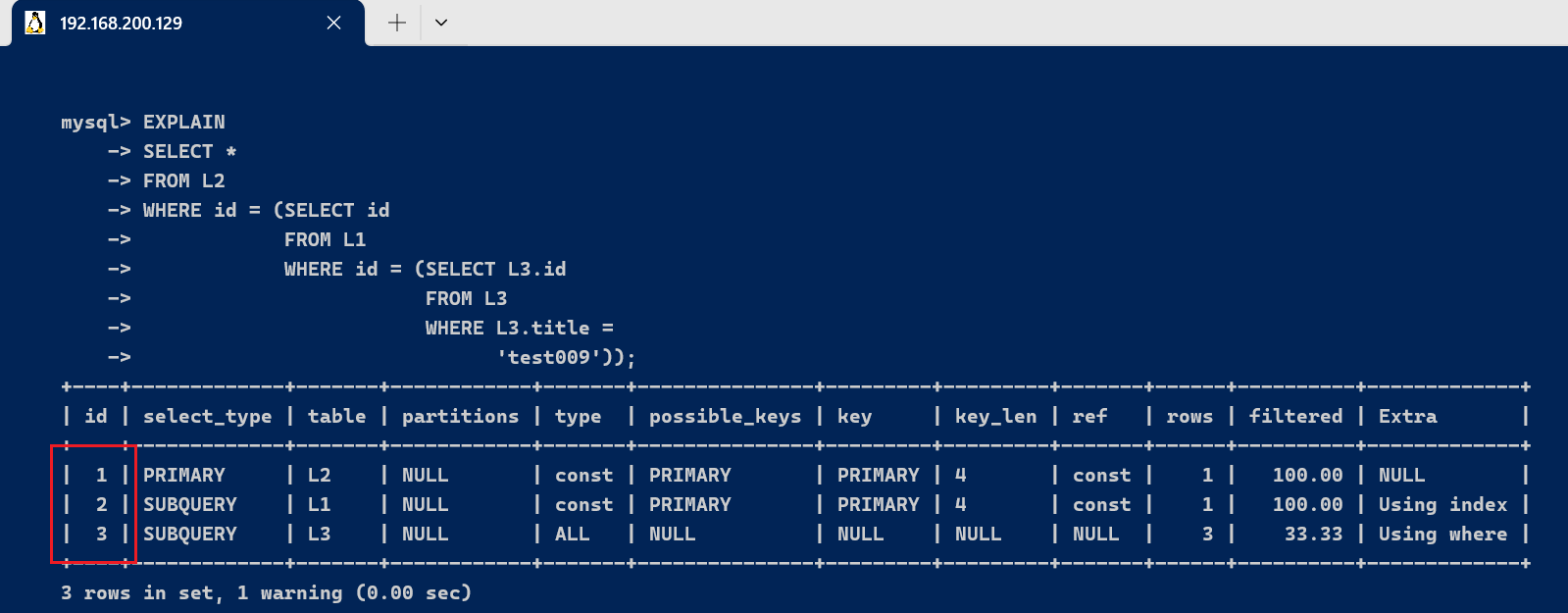
三、字段详解3.1、id字段select查询的序列号,包罗一组数字,表示查询中实行select子句或操作表的顺序
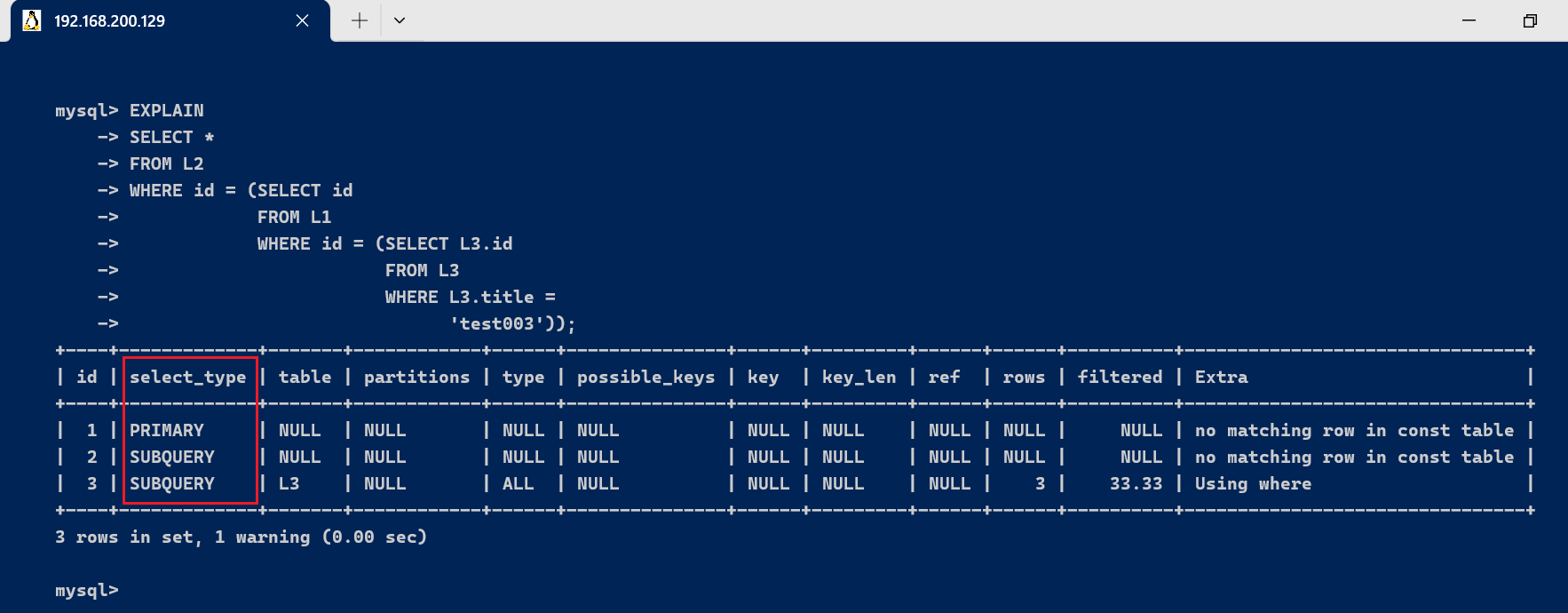
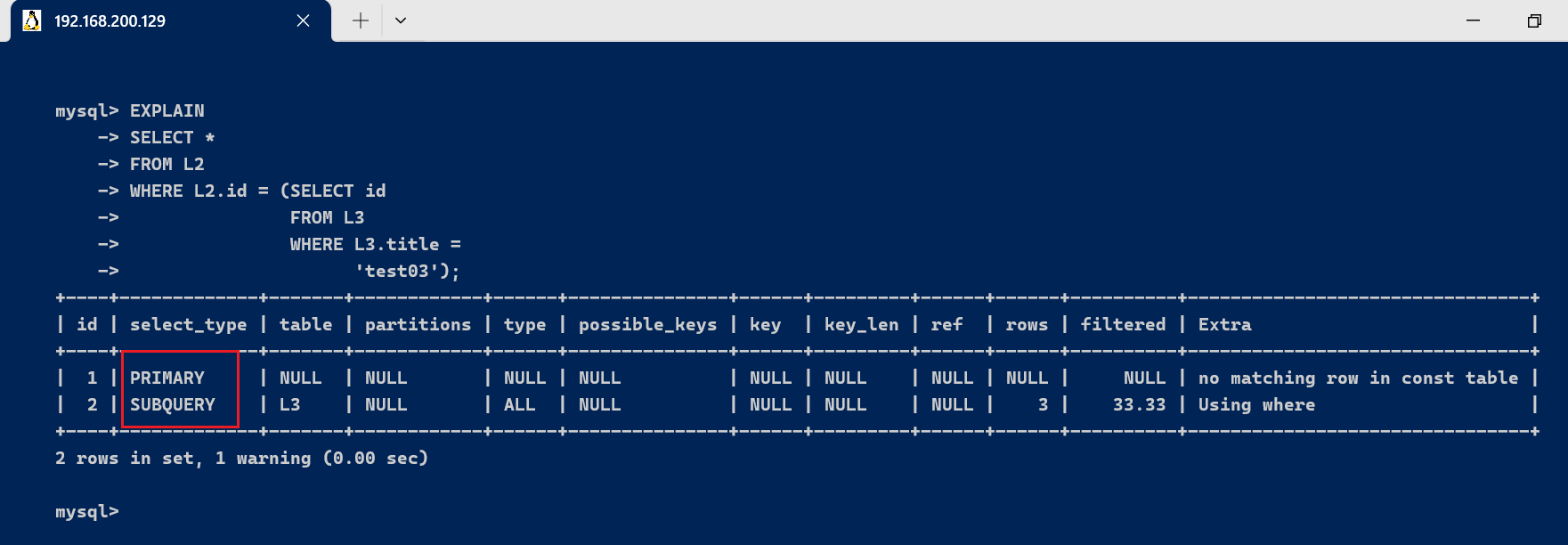
3.2、select_type 与 table字段查询类型,主要用于区别普通查询,联合查询,子查询等的复杂查询
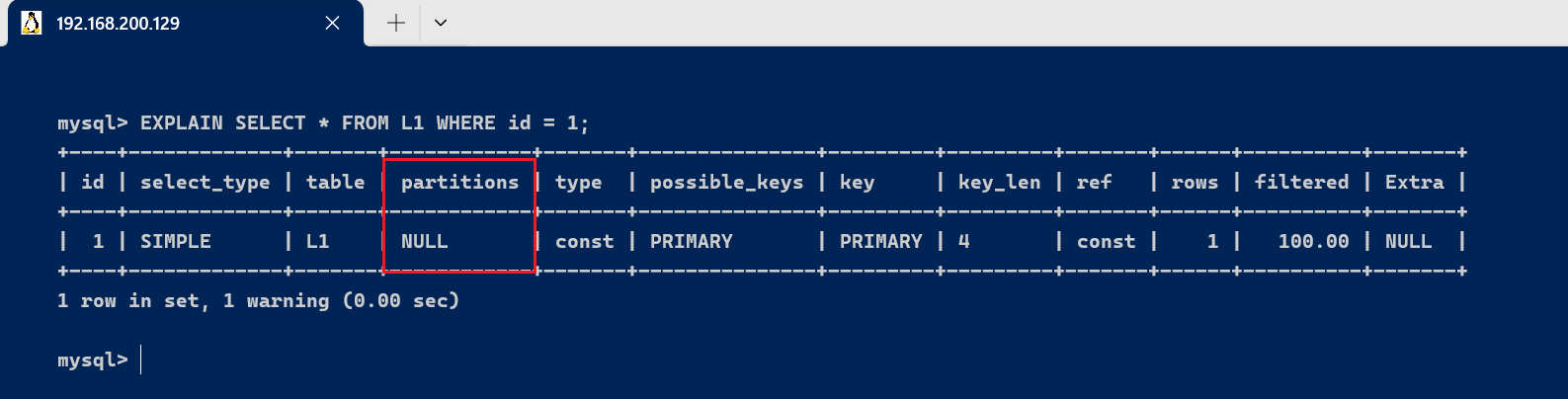
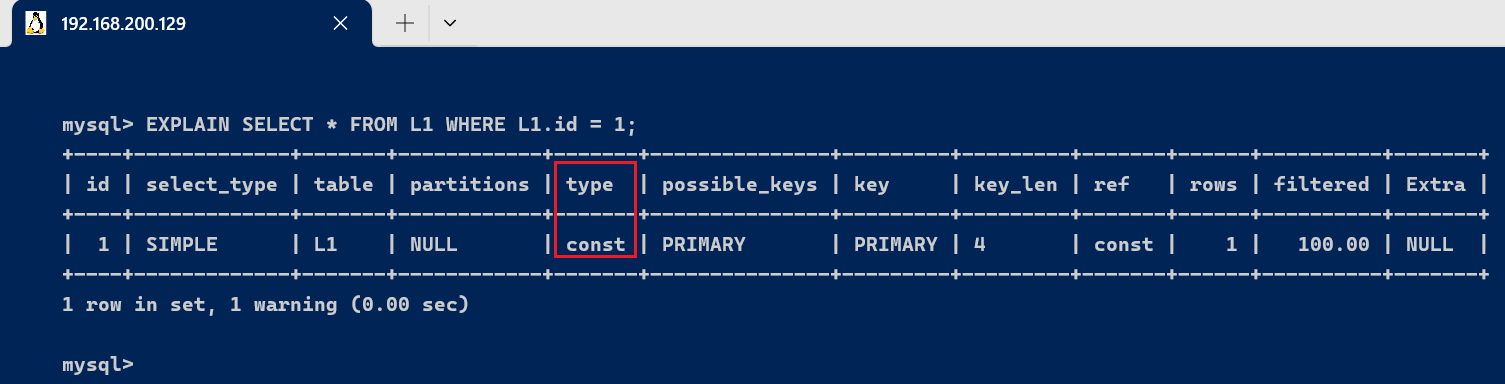
3.3、partitions分区表是将一个表的数据根据某个字段的值分成多个分区来存储的,如许查询时可以进步服从。 查询时匹配到的分区信息,对于非分区表值为NULL ,当查询的是分区表时, partitions 显示分区表命中的分区环境。 对于非分区表(例如原始的 [code]L1[/code] 表),[code]partitions[/code] 字段会显示 [code]NULL[/code]: [code]EXPLAIN SELECT * FROM L1 WHERE id = 1; [/code]
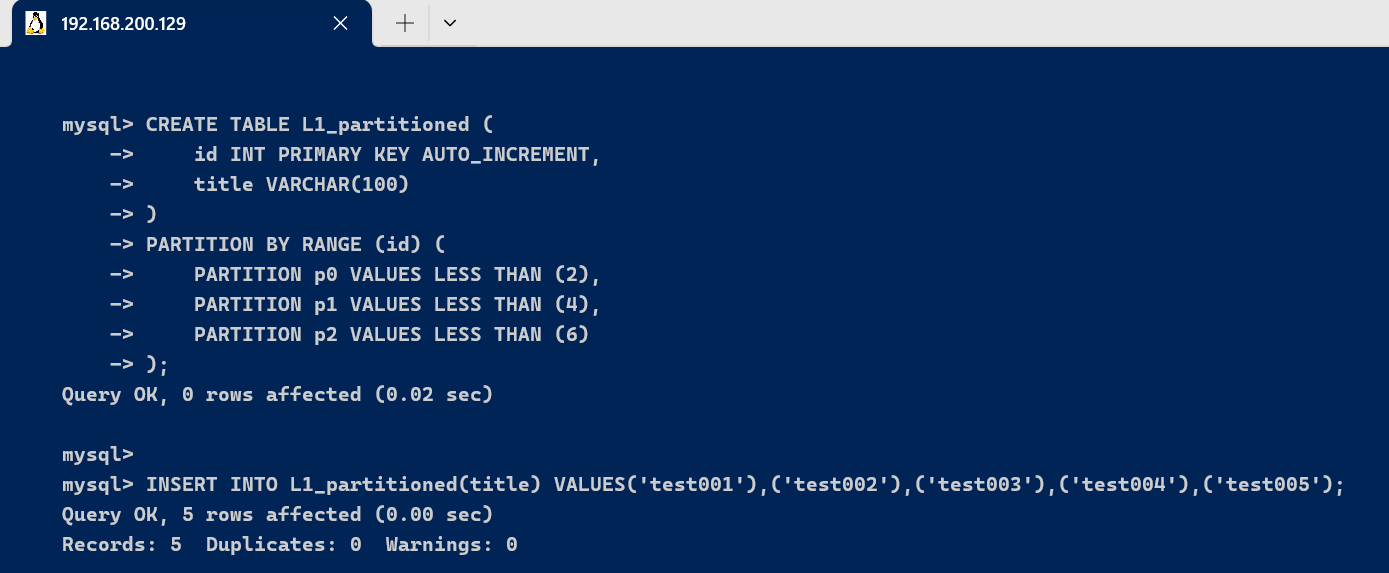
我们以 [code]L1[/code] 表为例,将它根据 [code]id[/code] 字段举行分区: [code]CREATE TABLE L1_partitioned ( id INT PRIMARY KEY AUTO_INCREMENT, title VARCHAR(100) ) PARTITION BY RANGE (id) ( PARTITION p0 VALUES LESS THAN (2), PARTITION p1 VALUES LESS THAN (4), PARTITION p2 VALUES LESS THAN (6) ); [/code] [code]INSERT INTO L1_partitioned(title) VALUES('test001'),('test002'),('test003'),('test004'),('test005'); [/code]这个表会根据 [code]id[/code] 的值分成 3 个分区:
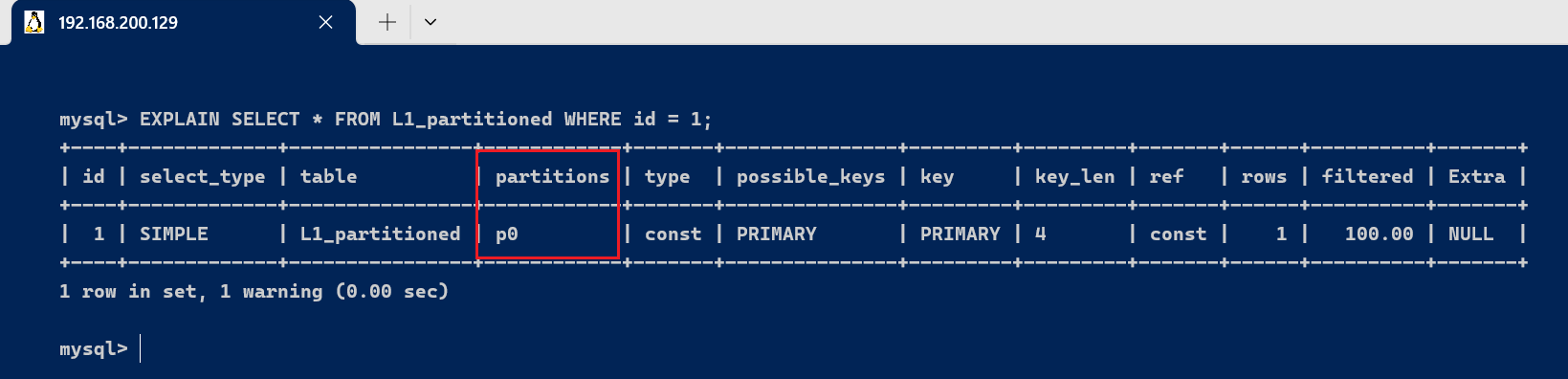
使用 [code]EXPLAIN[/code] 检察查询的分区命中环境: [code]EXPLAIN SELECT * FROM L1_partitioned WHERE id = 1; [/code]
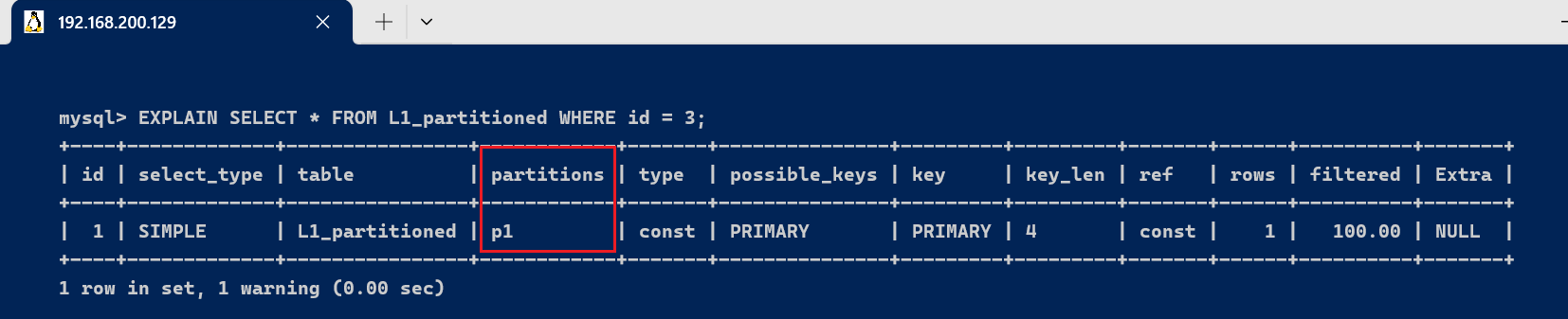
此查询会显示 [code]partitions[/code] 字段的值为 [code]p0[/code],由于 [code]id=1[/code] 的记载被存储在 [code]p0[/code] 分区中。 [code]EXPLAIN SELECT * FROM L1_partitioned WHERE id = 3; [/code]
此查询会显示 [code]partitions[/code] 字段的值为 [code]p1[/code],由于 [code]id=3[/code] 的记载被存储在 [code]p1[/code] 分区中。 当查询条件跨越多个分区时,[code]EXPLAIN[/code] 会显示命中的多个分区: [code]EXPLAIN SELECT * FROM L1_partitioned WHERE id BETWEEN 1 AND 5; [/code]
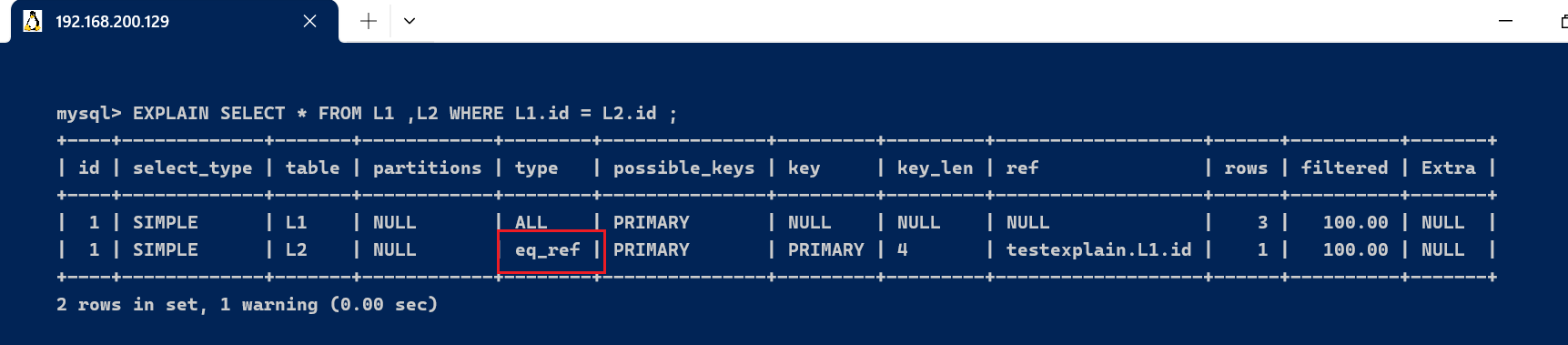
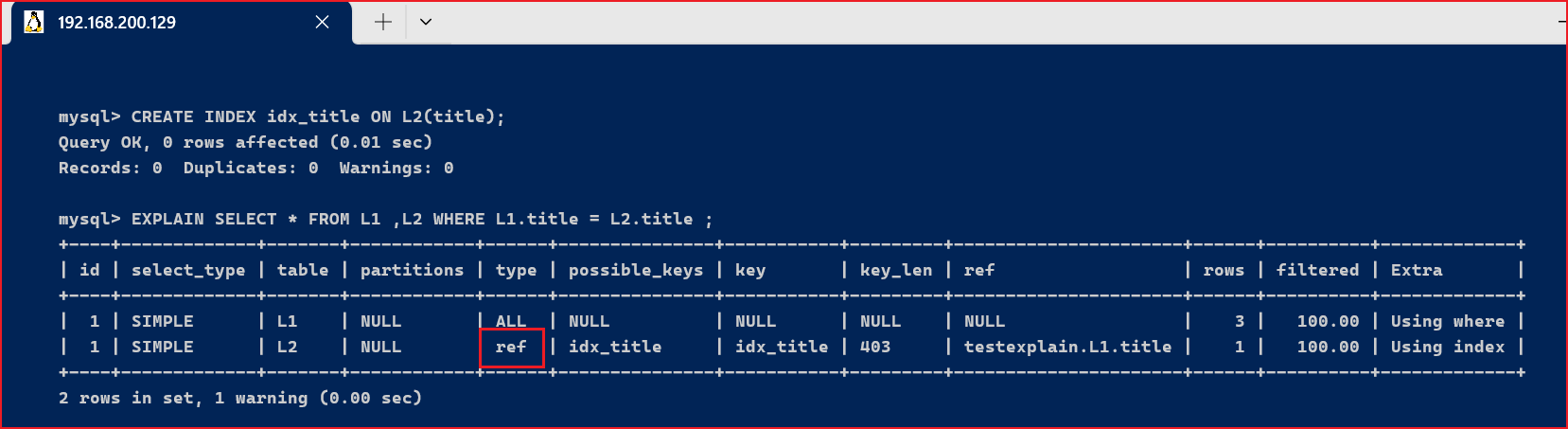
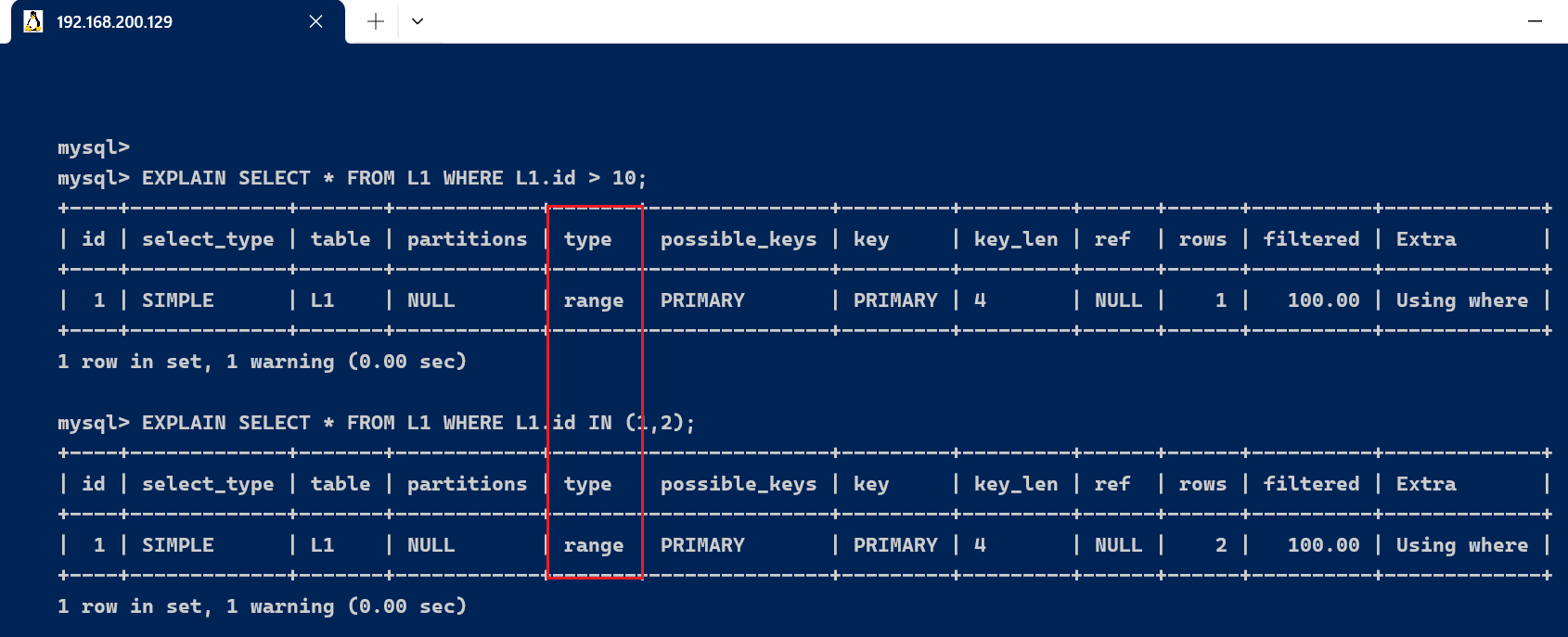
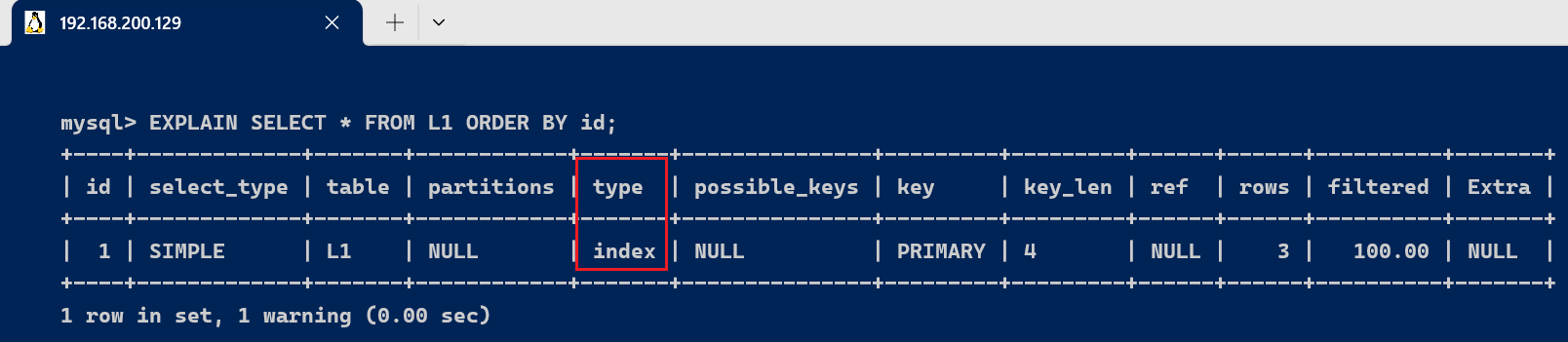
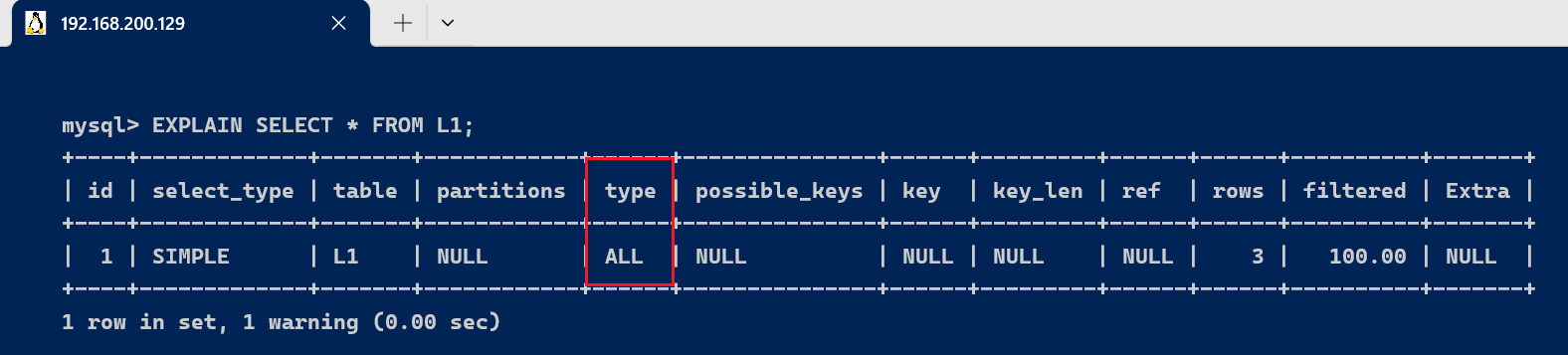
3.4、type字段type显示的是连接类型,是较为告急的一个指标。下面给出各种连接类型,按照从最佳类型到最坏类型举行排序: [code]system > const > eq_ref > ref > fulltext > ref_or_null > index_merge >unique_subquery > index_subquery > range > index > ALL [/code] [code]-- 简化 system > const > eq_ref > ref > range > index > ALL [/code]
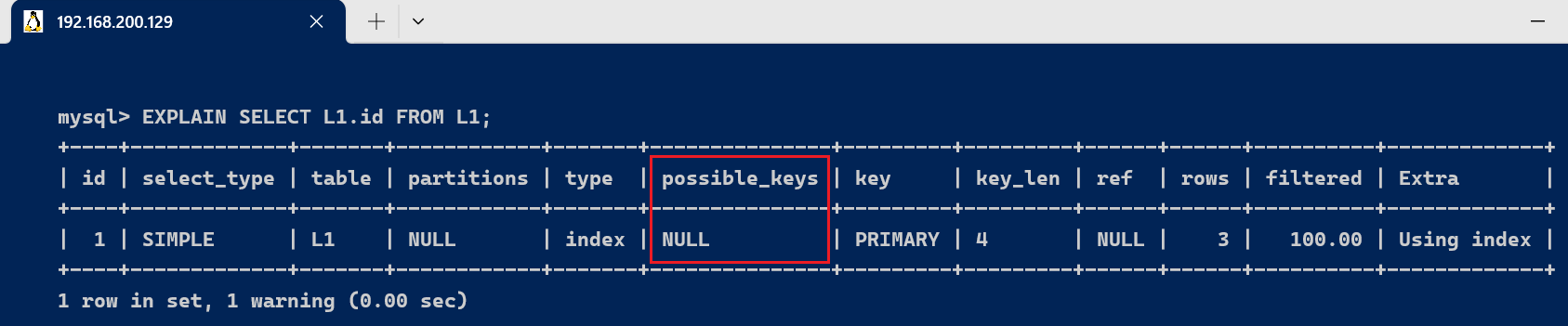
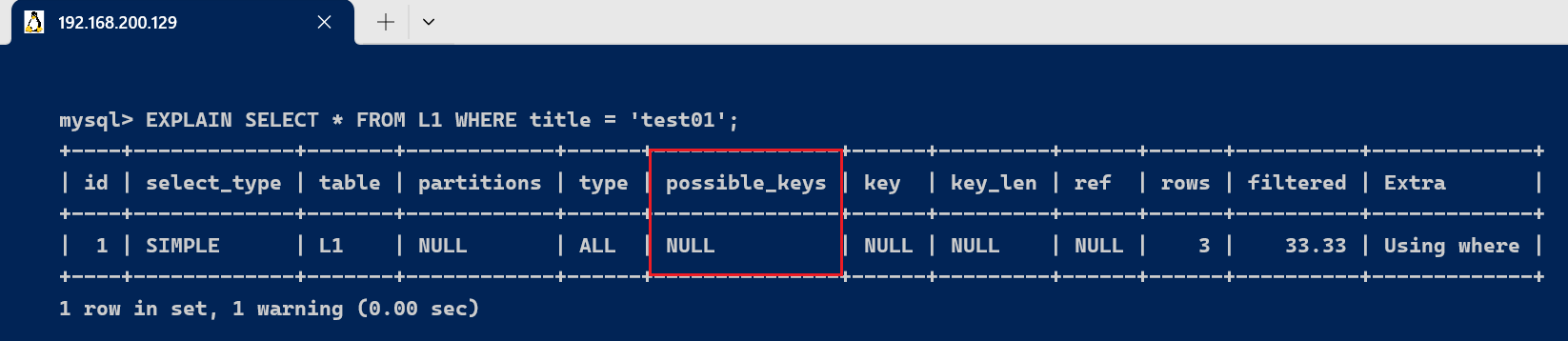
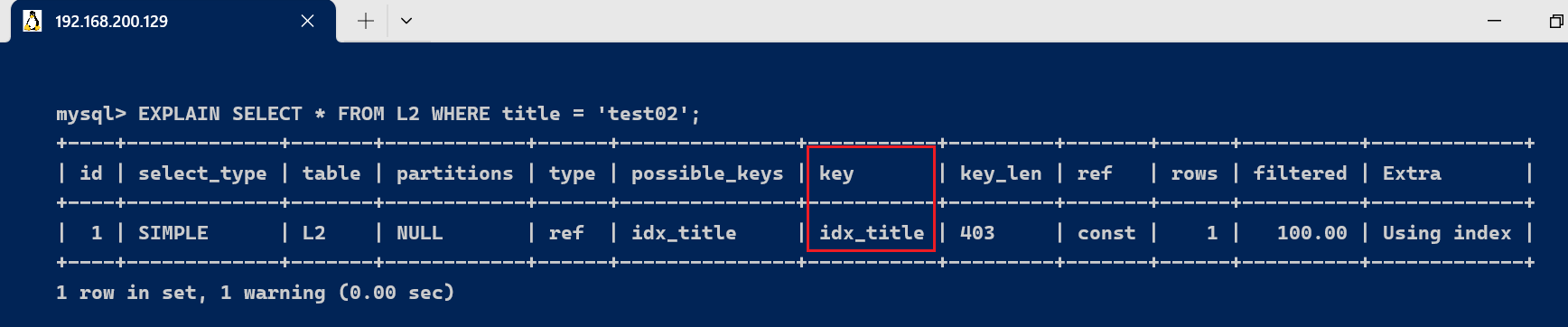
3.5、possible_keys 与 key字段
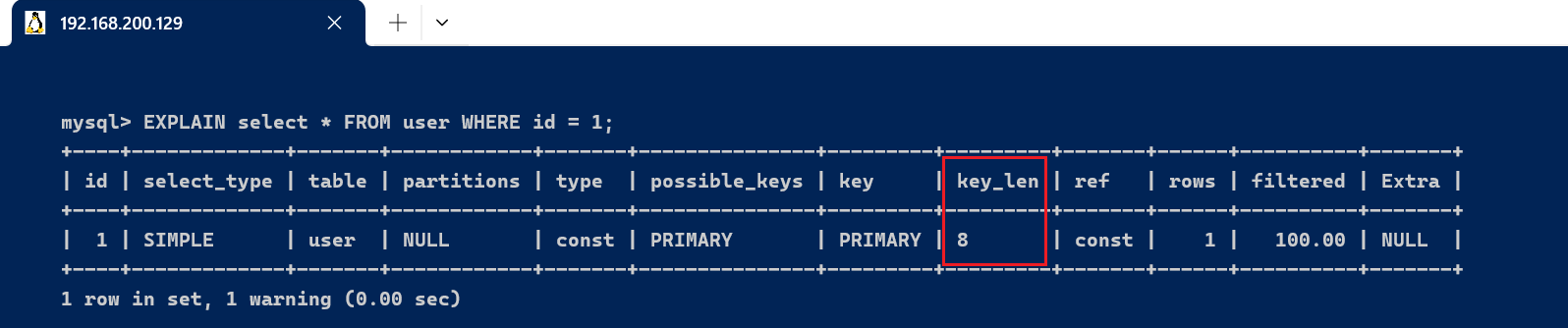
3.6、key_len字段表示索引中使用的字节数, 可以通过该列盘算查询中使用索引的长度. key_len 字段能够帮你查抄是否充实使用了索引 ken_len 越长, 分析索引使用的越充实 key_len表示使用的索引长度,key_len可以衡量索引的优劣,key_len越小 索引效果越好 [code]上述的这两句话是否存在矛盾呢,我们该怎么明确呢? 第一句:[code]key_len[/code] 越长,分析索引使用得越充实 表明:
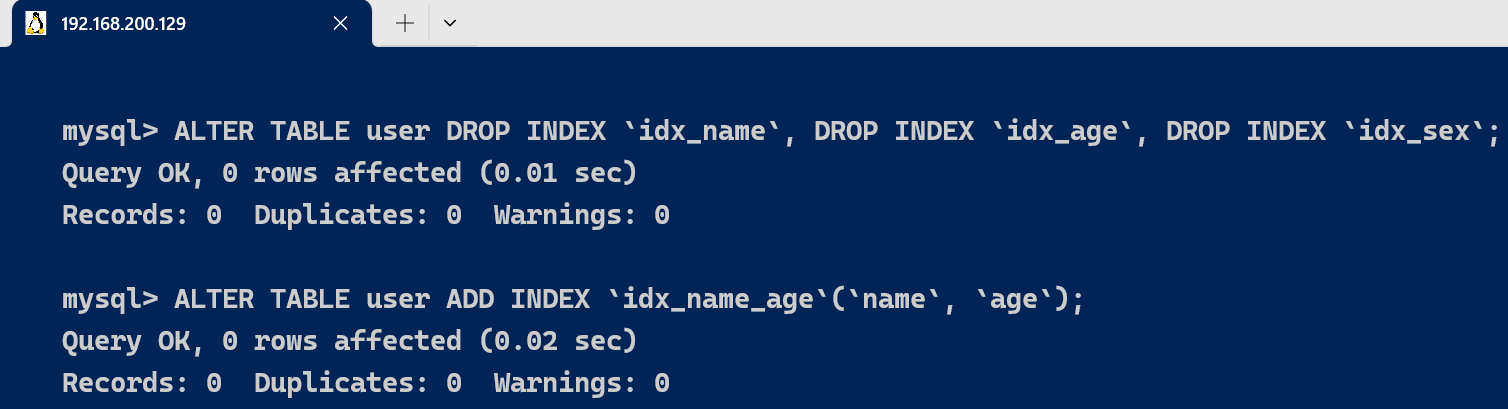
联合索引key_len盘算 我们删除user表其他辅助索引,创建一个联合索引 [code]ALTER TABLE user DROP INDEX `idx_name`, DROP INDEX `idx_age`, DROP INDEX `idx_sex`; [/code] [code]ALTER TABLE user ADD INDEX `idx_name_age`(`name`, `age`); [/code]
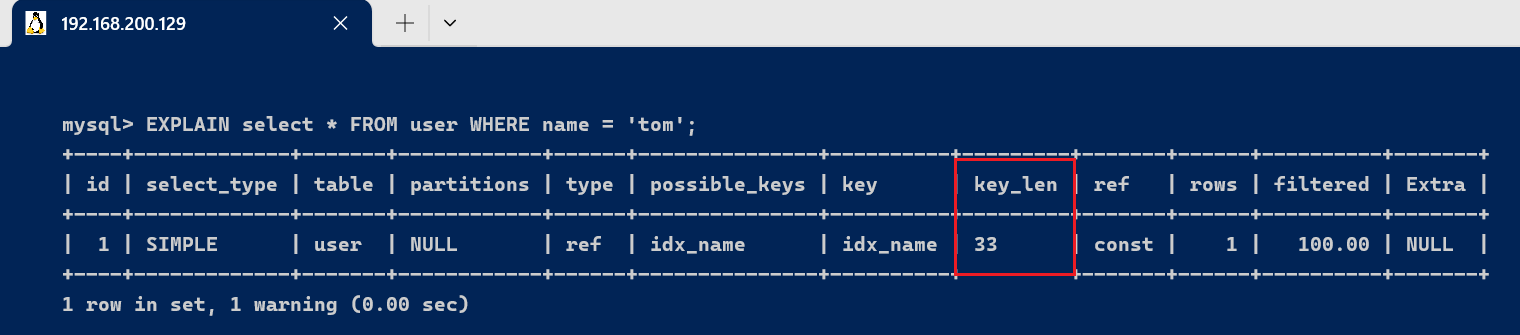
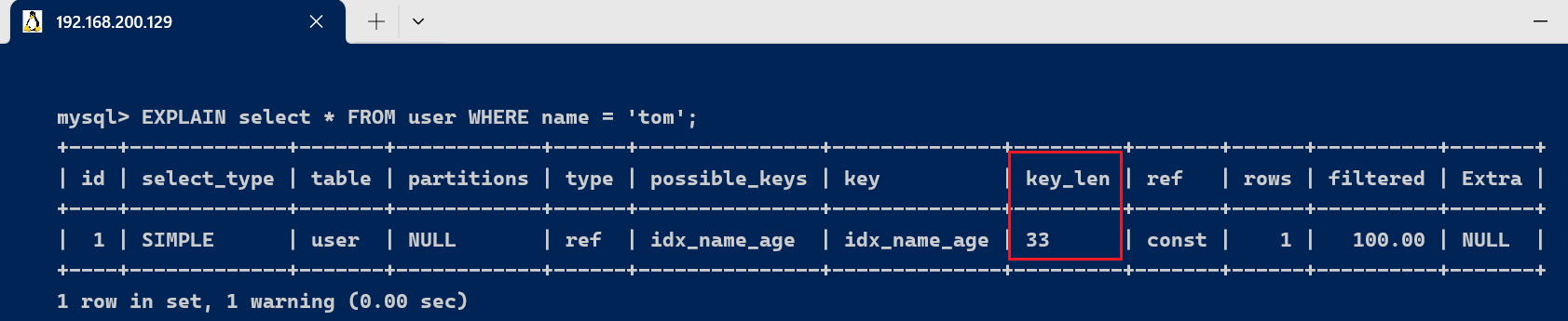
1、部分索引生效的环境 我们使用name举行查询 [code]EXPLAIN select * FROM user WHERE name = 'tom'; [/code]
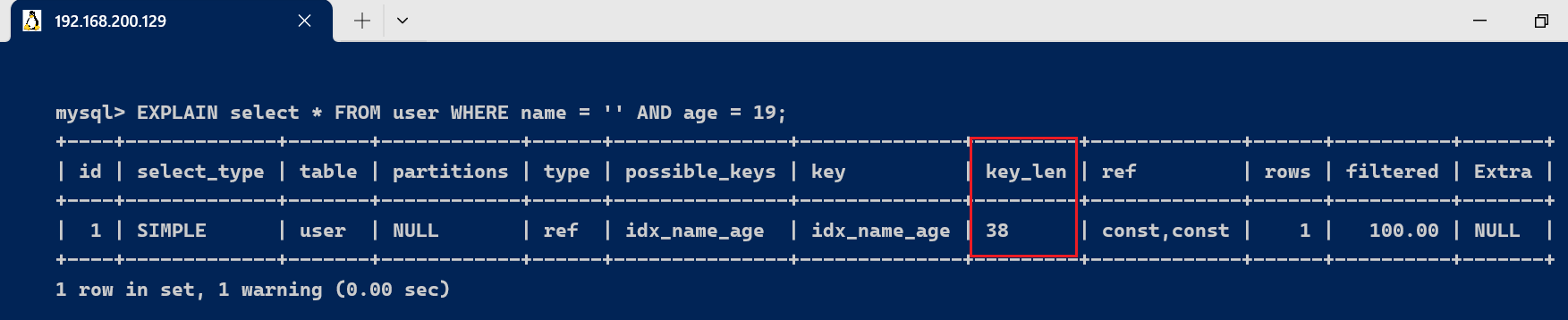
由于联合索引,根据最左匹配原则,使用到索引只有name这一列,name的字段类型是varchar(10),答应Null,字符编码是utf8,一个字符占用3个字节,varchar为动态类型,key长度加2,key_len = 10 * 3+2 + 1 = 33 。 2、联合索引完全使用索引的环境 [code]EXPLAIN select * FROM user WHERE name = '张三' AND age = 19; [/code]
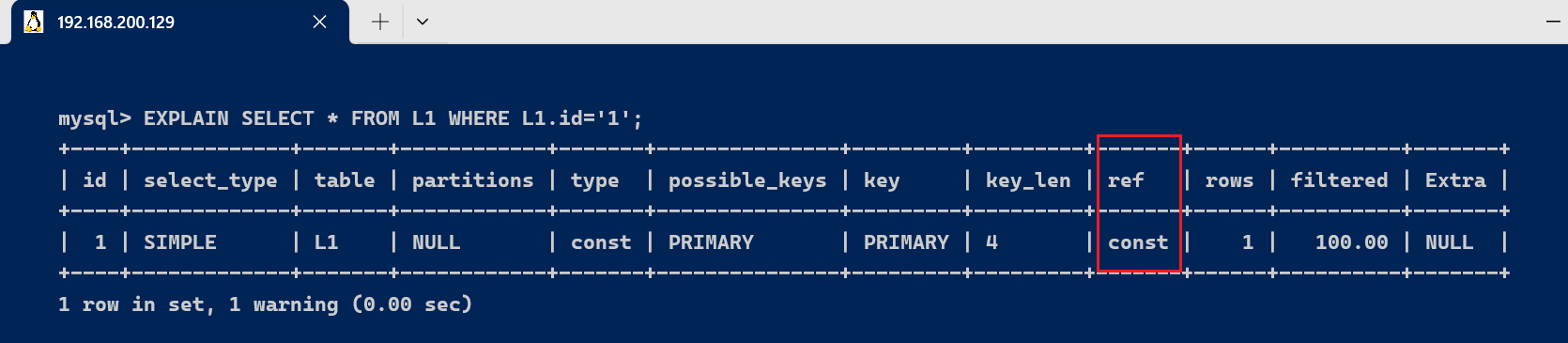
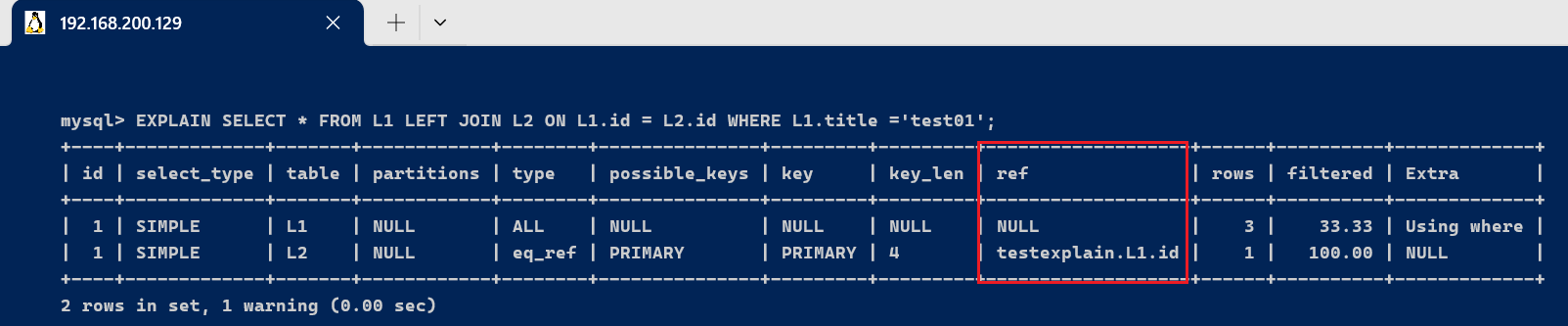
由于联合索引,使用到(name,age)联合索引,name的字段类型是varchar(10),答应Null,字符编码是utf8,一个字符占用3个字节,varchar为动态类型,key长度加2,key_len = 10 * 3 + 2 + 1 = 33 ,age的字段类型是int,长度为4,答应Null ,key_len = 4 + 1 = 5 。联合索引的key_len 为 key_len = 33+5 = 38。 3.7、ref 字段显示索引的哪一列被使用了,假如大概的话,是一个常数。哪些列或常量被用于查找索引列上的值
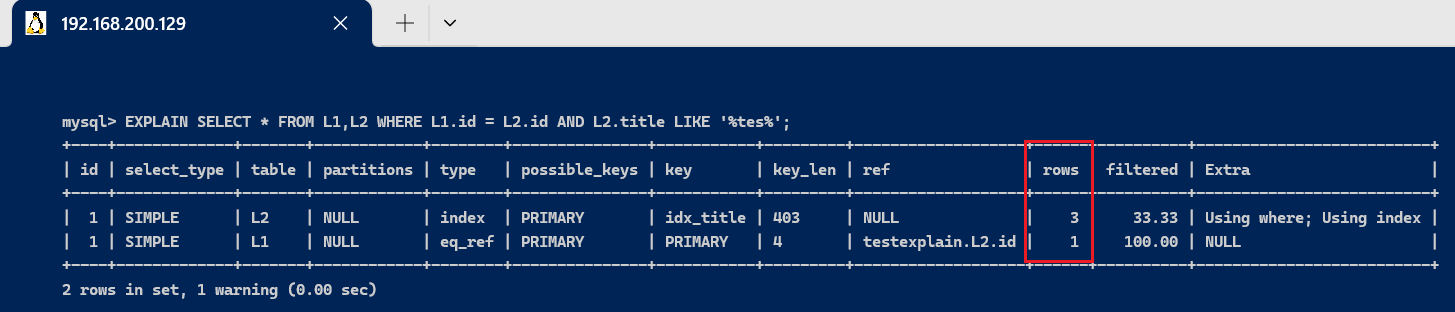
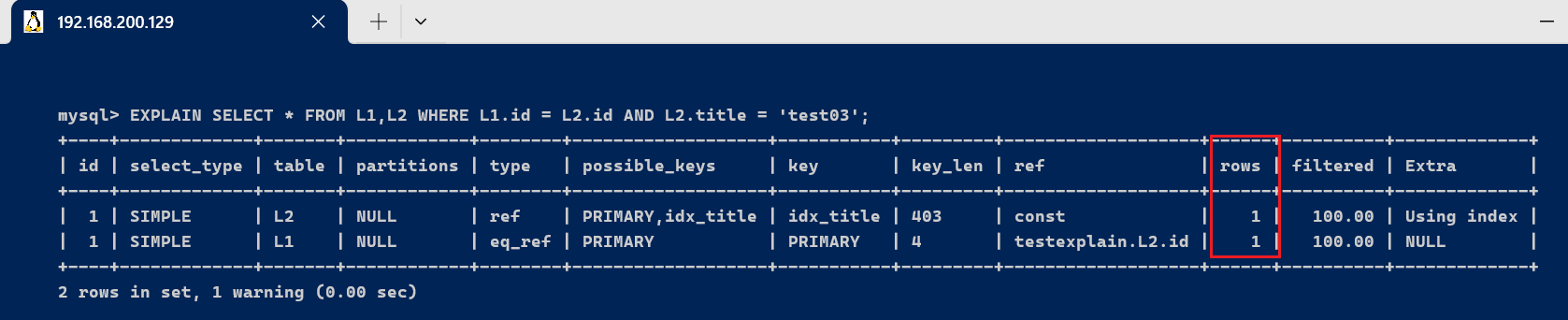
3.8、rows 字段表示MySQL根据表统计信息及索引选用环境,估算的找到所需的记载所必要读取的行数;越少越好
总结: 当我们必要优化一个SQL语句的时间,我们必要知道该SQL的实行计划,比如是全表扫描,照旧索引扫描; 使用explain 关键字可以模仿优化器实行sql 语句,从而知道mysql 是怎样处理sql 语句的,方便我们开发职员有针对性的对SQL举行优化.
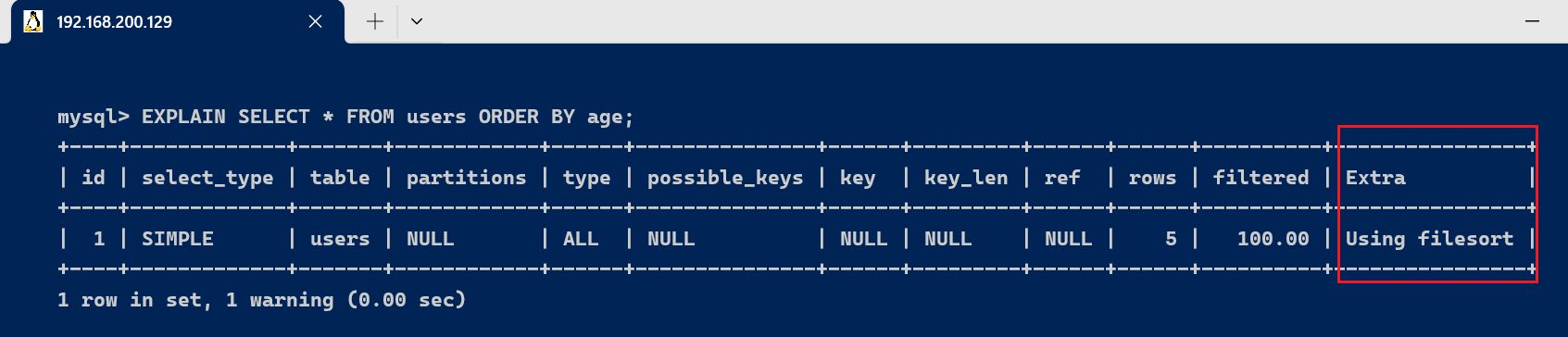
3.9、filtered 字段它指返回效果的行占必要读到的行(rows列的值)的百分比 3.9、extra 字段Extra 是 EXPLAIN 输出中别的一个很告急的列,该列显示MySQL在查询过程中的一些详细信息 [code]CREATE TABLE users ( uid INT PRIMARY KEY AUTO_INCREMENT, uname VARCHAR(20), age INT(11) ); INSERT INTO users VALUES(NULL, 'lisa',10); INSERT INTO users VALUES(NULL, 'lisa',10); INSERT INTO users VALUES(NULL, 'rose',11); INSERT INTO users VALUES(NULL, 'jack', 12); INSERT INTO users VALUES(NULL, 'sam', 13); [/code]
实行效果Extra为Using filesort ,这分析,得到所需效果集,必要对所有记载举行文件排序。这类SQL语句性能极差,必要举行优化。 典型的,在一个没有创建索引的列上举行了order by,就会触发filesort,常见的优化方案是,在order by的列上添加索引,克制每次查询都全量排序。 filtered 它指返回效果的行占必要读到的行(rows列的值)的百分比
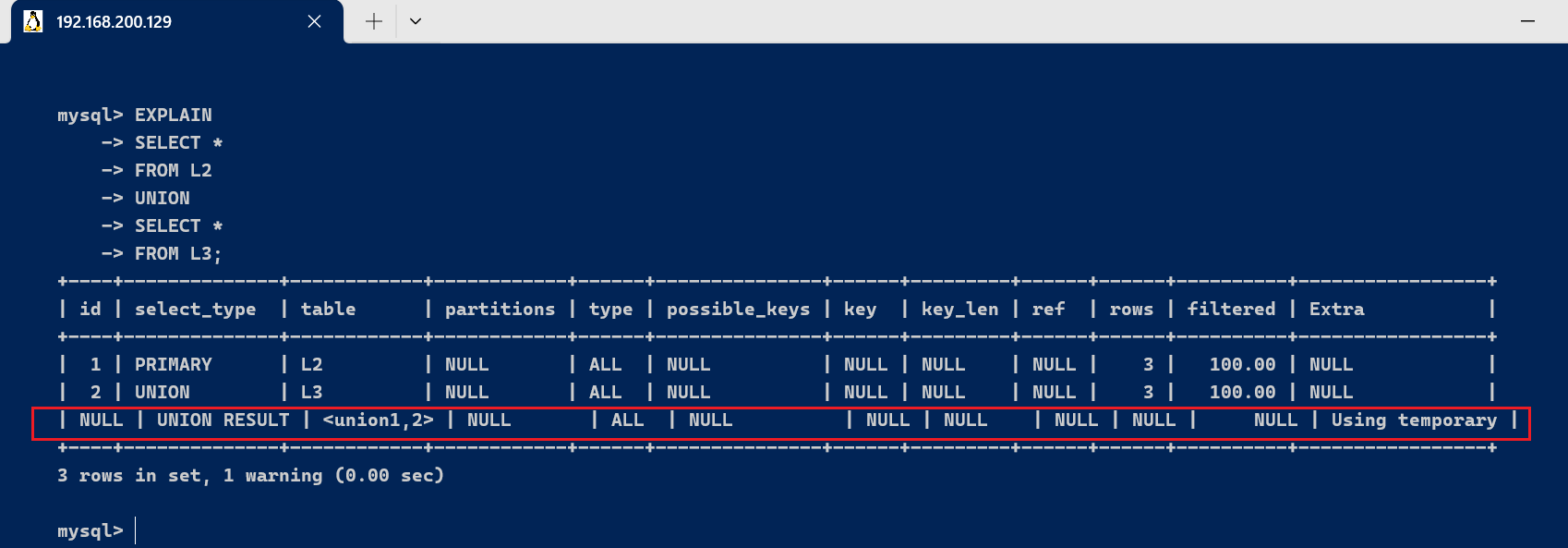
实行效果Extra为Using temporary ,这分析必要创建临时表 (temporary table) 来暂存中央效果。性能消耗大, 必要创建一张临时表, 常见于group by语句中. 需共同SQL实行过程来表明, 假如group by和where索引条件差别, 那么group by中的字段必要创建临时表分组后再回到原查询表中.假如查询条件where和group by是雷同索引字段, 那么就不必要临时表.
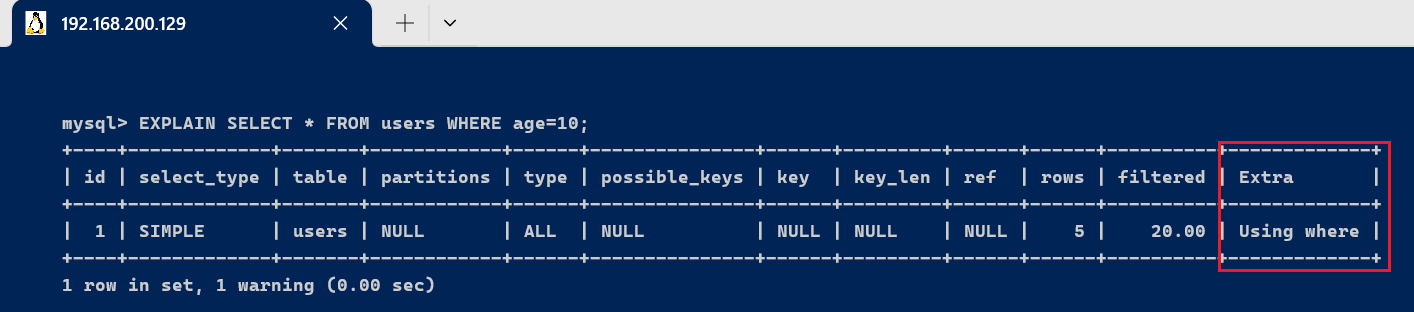
此语句的实行效果Extra为Using where,表示使用了where条件过滤数据。必要留意的是:
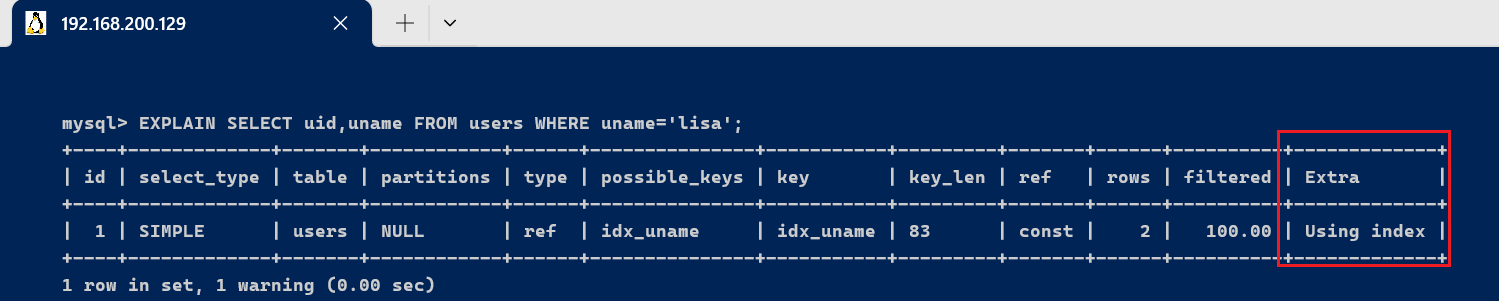
表示直接访问索引就能够获取到所必要的数据(覆盖索引) , 不必要通过索引回表. [code]-- 为uname创建索引 alter table users add index idx_uname(uname); [/code] [code]EXPLAIN SELECT uid,uname FROM users WHERE uname='lisa'; [/code]
此句实行效果为Extra为Using index,分析sql所必要返回的所有列数据均在一棵索引树上,而无需访问现实的行记载。
必要举行嵌套循环盘算. [code]ALTER TABLE users ADD COLUMN sex CHAR(1); [/code] [code]UPDATE users SET sex = '0' WHERE uname IN ('lisa', 'rose'); UPDATE users SET sex = '1' WHERE uname IN ('jack', 'sam'); [/code] [code]EXPLAIN SELECT * FROM users u1 LEFT JOIN (SELECT * FROM users WHERE sex = '0') u2 ON u1.uname = u2.uname; [/code]
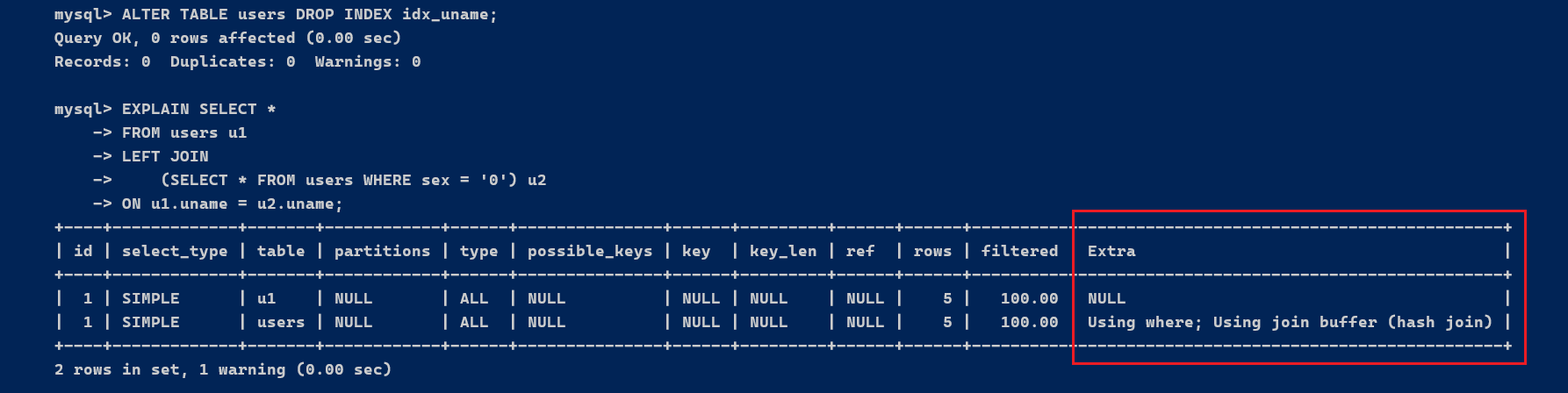
没有显示 [code]Using join buffer[/code],大概是由于查询优化器在这个详细的场景下能够有效地使用索引,因此不必要使用连接缓冲区。在这种环境下,MySQL 直接使用了 [code]ref[/code] 类型的连接(通过索引举行连接),而不是必要缓冲区的嵌套循环连接。 可以删除或修改表上的索引,以便让 MySQL 在实行查询时无法使用现有的索引,从而被迫使用连接缓冲区。 [code]ALTER TABLE users DROP INDEX idx_uname; [/code] [code]EXPLAIN SELECT * FROM users u1 LEFT JOIN (SELECT * FROM users WHERE sex = '0') u2 ON u1.uname = u2.uname; [/code]
实行效果Extra为Using join buffer (Block Nested Loop) 分析,必要举行嵌套循环盘算, 这里每个表都有五条记载,内外表查询的type都为ALL。 题目在于 两个关联表join 使用 uname,关联字段均未创建索引,就会出现这种环境。 常见的优化方案是,在关联字段上添加索引,克制每次嵌套循环盘算。
搜索条件中固然出现了索引列,但是有部分条件无法使用索引,会根据能用索引的条件先搜索一遍再匹配无法使用索引的条件。 Using index condition 叫作 Index Condition Pushdown Optimization (索引下推优化)。Index Condition Pushdown (ICP)是MySQL使用索引从表中检索行的一种优化。假如没有ICP,存储引擎将遍历索引以定位表中的行,并将它们返回给MySQL服务器,服务器将判定行的WHERE条件。在启用ICP的环境下,假如可以只使用索引中的列来盘算WHERE条件的一部分,MySQL服务器就会将WHERE条件的这一部分推到存储引擎中。然后,存储引擎通过使用索引条目来评估推入的索引条件,只有当满意该条件时,才从表中读取行。ICP可以减少存储引擎必须访问基表的次数和MySQL服务器必须访问存储引擎的次数。 [code]CREATE TABLE employees ( id INT PRIMARY KEY AUTO_INCREMENT, first_name VARCHAR(50), last_name VARCHAR(50), age INT, department_id INT, salary DECIMAL(10, 2), hire_date DATE ); INSERT INTO employees (first_name, last_name, age, department_id, salary, hire_date) VALUES ('John', 'Doe', 30, 1, 60000.00, '2015-03-01'), ('Jane', 'Doe', 28, 2, 65000.00, '2016-07-15'), ('Mike', 'Smith', 45, 3, 75000.00, '2010-10-22'), ('Sara', 'Jones', 32, 1, 55000.00, '2018-01-12'), ('Tom', 'Brown', 29, 2, 58000.00, '2017-05-18'); [/code]接着,我们在 [code]last_name[/code] 和 [code]age[/code] 字段上创建复合索引: [code]CREATE INDEX idx_lastname_age ON employees(last_name, age); [/code]编写一个查询,包罗部分能使用索引的条件和部分不能使用索引的条件: [code]EXPLAIN SELECT * FROM employees WHERE last_name = 'Doe' AND age > 25 AND salary > 60000; [/code]
这一行表明 MySQL 在查询中使用了 [code]Index Condition Pushdown[/code] 优化。 在这个例子中,[code]last_name = 'Doe'[/code] 和 [code]age > 25[/code] 可以使用复合索引 [code]idx_lastname_age[/code],因此 MySQL 使用索引条件下推技能,在存储引擎层面尽量减少访问行数据的次数。 [code]salary > 60000[/code] 是不能使用索引的条件,但由于使用了 ICP,存储引擎会先根据 [code]last_name[/code] 和 [code]age[/code] 举行初步过滤,然后再把符合条件的行返回给 MySQL 服务器,服务器进一步应用 [code]salary > 60000[/code] 的过滤。 总结: Index Condition Pushdown (ICP) 是一种优化技能,答应 MySQL 在存储引擎层面应用部分 [code]WHERE[/code] 条件,从而减少必要从表中读取的行数。这可以进步查询性能,尤其是在涉及复合索引时。 [code]Using index condition[/code] 提示表示 MySQL 已经应用了 ICP 优化。通过使用复合索引和带有多条件的查询,可以显式地观察到这个优化技能的作用。 到此这篇关于MySQL中EXPLAIN的/基本使用及字段详解的文章就先容到这了,更多相关MySQL中EXPLAIN详解内容请搜索脚本之家从前的文章或继承浏览下面的相关文章盼望各人以后多多支持脚本之家! 来源:https://www.jb51.net/database/327227wiu.htm 免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
 /6
/6 
 |手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
|手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
GMT+8, 2025-7-2 08:52 , Processed in 0.043729 second(s), 18 queries .
Powered by Mxzdjyxk! X3.5
© 2001-2025 Discuz! Team.