目录Mysql大表全表查询当我们需要对一整张大表的数据实行全量查询操纵,比如select * from t 没有where条件,整个数据有几千万条占用内存大概 100G,而Mysql地点服务器的内存只有8G,那就不直接OOM,将整个数据库打崩了吗? 刚开始开发的时候会有这样的疑问,但是随着时间的推移知道是不会打崩的,但是为什么不会崩,渐渐地就没有好奇心了。 下面对整个流程举行分析,主要的打击点就是Mysql和InnoDB,所以下面还是分成两个部分举行分析。 下面的分析同样适用于全部的查询流程,只是其他查询操纵流程更复杂,但是数据量无论巨细都会按照下面的流程实行。 查询整张表着实就是查询 主键聚簇索引的那棵B+树,比如查询的就是InnoDB 表 db1. t。 查询和返回按照java方式理解为 request和response流程,request查询流程可以理解为:Mysql架构图 ,即下面分析的是返回的流程: 1、Server层Server层不会一次调用InnoDB存储引擎接口获取全量数据,也不是一次将全部数据发生给Mysql客户端,Mysql是边读边发送的,发送的过程中依靠两个缓存池:
具体的查询实行流程如下:
而且在此数据查询过程当前,底层的表现就是Mysql服务端的socket send buffer 和 Mysql客户端 socket receive buffer,在不绝的发生和接收数据包,由于底层是tcp协议。 而从表象上看,实行 show processlist,查询到的结果为 Sending to client,所以不能简朴的理解成发生数据给客户端,仅仅表示服务器端的网络栈写满了。
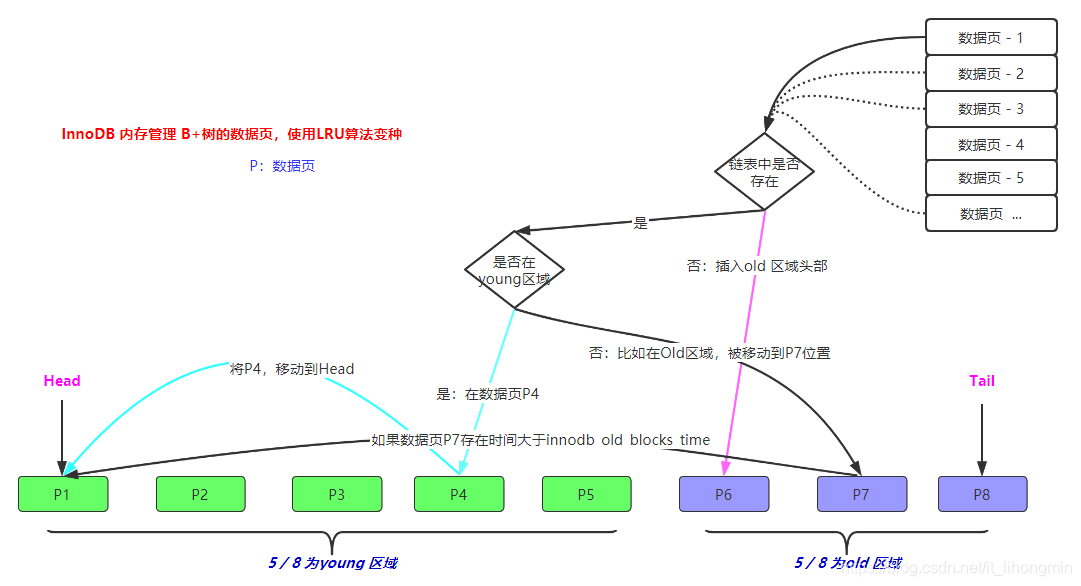
2、innoDB层在前面博客分析了InnoDB的架构图,分为内存和磁盘架构。内存架构中最大的一块儿内存就是 Buffer Pool,可以占用到物理内存的 60~80%。 而且分析了针对当前这种大表查询流程,会将全部的B+树缓存页都在变种的 LRU缓存队列中过一遍。 所以Mysql将缓存链表分成young和old区,利用设置参数 innodb_old_blocks_time控制缓存页真正加入的young取余的条件。 即大表查询流程对innodb层的影响就是,将全部主键聚簇索引B+树上的页,全部在 Buffer Pool内部的 LRU链的 old地域全部实行一遍,当凌驾内存巨细限定时,再从 old链的尾部出队列。流程图如下:
总结以上为个人经验,希望能给各人一个参考,也希望各人多多支持脚本之家。 来源:https://www.jb51.net/database/3258094rc.htm 免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
 /6
/6 
 |手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
|手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
GMT+8, 2025-8-16 02:00 , Processed in 0.030214 second(s), 19 queries .
Powered by Mxzdjyxk! X3.5
© 2001-2025 Discuz! Team.