|
|

5 z+ V- }0 ]8 r$ H9 J+ t. p; _$ i2 n* |9 Q
) R+ O- I }2 Z. D# D8 A1 S. n/ ] J3 m10月23日,在北京召开的2019 Arm技术峰会上,Arm正式发布了全新的Ethos-N77/N57/N37系列NPU IP,进一步加码人工智能(AI)计算。与此同时,Arm还推出了针对主流移动游戏市场的高能效的Mali G57 GPU和针对主流及入门级市场的单位面积最高效的Mali-D37 DPU。
4 \, a- }% U- f8 k- I4 W, H3 C* L# k3 ^: N g) g/ K: q
# v( L* C9 G8 IARMv8及后续架构将不受限制的继续支持中国合作伙伴!
! ^: G8 |6 S8 v# g
L) p; r. N+ s ^# ?, d
: J+ Y* J2 V( P' `6 O, e+ ~: u ]今年9月25日,Arm中国在深圳召开媒体沟通会,针对此前外界盛传的“Arm断供华为”一事,Arm表示与华为仍是合作伙伴,ARMv8及后续V9指令集可继续授权!6 A4 Y5 c" \- E$ o( W
' L# n4 F8 h1 c7 W& {# B! s. u
4 i# k4 h" p( Y/ v7 }10月23日,在2019 Arm技术峰会北京站上,Arm董事长兼CEO吴雄昂在开场致辞当中再度重申,经过法务严谨的调查及相关调整,目前无论是ARMv8,还是后续的V9架构都是源自英国的技术,将可不受限制的继续支持中国的合作伙伴!. W" a, l I# Y; I9 B
0 w% X2 R& O$ u% x. Q |0 F
! g! X" J$ c; [1 l C1 ~8 f6 { 6 ]0 q7 g1 ~% P. _- _ 6 ]0 q7 g1 ~% P. _- _
. z8 j7 a, }* j5 N! N$ Z8 F
& f9 z4 m4 {6 B' D/ i0 R( D此外,吴雄昂还指出,Arm在中国的合作伙伴已经超过200家,中国合作伙伴出货的基于Arm架构的芯片已超过了160亿颗,国产SoC芯片95%都是基于Arm架构的。6 Z0 N, N1 n5 y$ b9 g* h, a6 }0 u
) [- E. I6 ^3 K* G! {
$ E: `* A& O8 s/ Z7 o吴雄昂强调,Arm是唯一非源于美国的主流计算架构。Arm中国承接Arm在中国的业务和技术,在Arm标准之下自主创新、赋能产能,把中国工程师能力调动起来打造知识产权。这些知识产权将不只是提供给中国产业,还要通过统一标准面向全球。$ ]; h6 I0 b+ t% U& F! d S ]5 F
+ _* k) t% V0 ]. x
" j5 {: c3 u! }& N
加码AI计算,Arm发布Ethos系列NPU IP
7 {& I' x- u8 \" p; O/ E3 z
: ]) y f8 P# A7 @" ?1 q7 Z7 f p6 I
根据Arm及研究机构的预计,到 2028 年,移动设备的数量将从现在的17亿台增长到 22 亿台,智能的IP Camera将由现在的1.6亿台增长到13亿台。在终端侧具有人工智能的设备将会由现在的3亿台增长到32亿台。足见人工智能市场增长之迅速。" q; V. ~0 g7 b
7 [% ~8 d8 |) t6 E" W+ [5 x$ p
0 z$ y: i+ t! Z4 r) c( D; c而随着AI技术的兴起和广泛应用,AI对于芯片的算力也提出了更高的要求。作为全球最大的处理器IP供应商,Arm的Cortex CPU和Mali GPU在以智能手机为代表的移动终端市场占据了极大的市场份额,但是在AI计算领域,Arm此前一直都是依托于其Cortex CPU、Mali GPU及相关软件开发工具来提升其AI计算的能力。9 h) P! W2 V0 M8 H/ Y7 j
/ T; y! A! s3 h; y5 {) t8 s+ o) p7 `3 u9 {6 x3 C
但是,传统的CPU、GPU核心并不是AI计算的最佳载体。因此越来越多的芯片厂商开始推出了AI专用芯片,或者在SoC当中加入AI计算专用的NPU内核。比如华为2017年就率先推出了集成NPU内核的麒麟970处理器,同时苹果推出的A11处理器也首次集成了NPU内核。此后,高通、联发科、三星、展锐等手机芯片厂商也纷纷开始在SoC当中集成自己的NPU内核。' K9 \; Y: f& U
) v+ ]7 F% m7 u
7 O4 R6 C: h/ J6 t9 @3 N5 H0 M5 [在此趋势之下,为了应对市场对于AI内核的需求,Arm在2018年年初也公布了针对AI的Project Trillium项目,其中就包括了全新的机器学习处理器IP、目标检测处理器IP和神经网络软件库。经过了近两年的时间,现在Project Trillium项目的成果也开始正式产品化。
7 M" J9 M. q& {7 q$ q' z
" s9 @; k7 W, L0 k
, B3 V1 G6 h& X |2 f5 v* t, P' Z8 h0 J: l
1 _1 Z, c+ j5 O4 R: b( _
( Y# |: W( N- H
" G( D! G3 h5 t8 h% r9 v
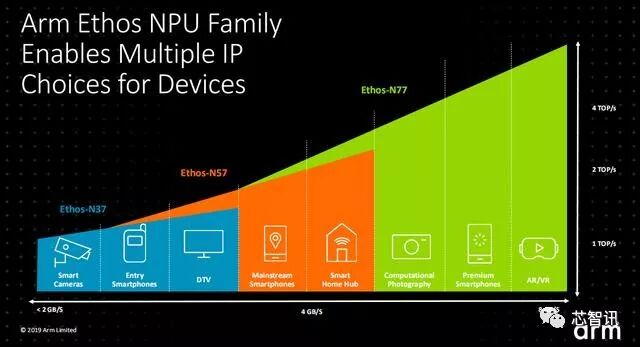
L; K3 o& G, S r今天,Arm市场营销副总裁Ian Smythe 在Arm技术峰会上正式发布了全新的Ethos系列NPU IP,包括针对高端市场的Ethos-N77、针对主流市场的Ethos-N57和低端市场的Ethos-N37。
5 a$ \( z. N, b l# P# ?& b1 f
* D% k9 O6 I( n$ }0 C' B; c) V$ \2 H+ S( ^+ w6 X5 d! k
# A2 U O& a) w& G/ }
% C$ \3 y0 a% [: V
! w! h6 h9 J& ?* T$ C: f* `! U2 V! h: ]
Ethos-N77实际上就是Arm去年公布的Project Trillium项目中的那款机器学习处理器IP,其内部集成了可配置的1-4MB的SRAM,在1GHz主频下,7nm工艺下,可以提供最高4 TOPS的AI算力,每瓦性能高达5 TOP。另外,之前Project Trillium项目公布的数据显示,Ethos-N77的单位面积算力为4.6 TOPs/mm²(最新发布的可能有进一步提升)。那么Ethos-N77的这个性能在市场上处于什么水平呢?
) p' {, t/ @8 y j& L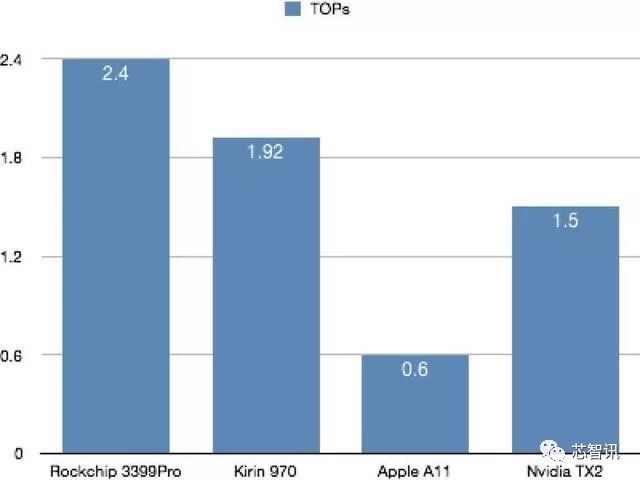 0 E" G$ l9 Z# x1 \5 Z8 N 0 E" G$ l9 Z# x1 \5 Z8 N
根据资料显示,华为麒麟970 NPU是基于寒武纪1A IP,算力是1.92TOPS。而苹果A11的NPU算力仅为0.6 TOPS,A12的NPU性能为5TOPS。而根据此前高通骁龙855发布之时的数据显示,其整体(包括CPU+GPU+DSP等)的AI算力(超过7 TOPS)是华为麒麟980的两倍,照此估算的话,麒麟980的NPU性能大概在3.5 TOPS左右。另外据芯智讯了解,华为麒麟980的NPU是基于寒武纪IH8,是针对低功耗场景视觉领域的NPU内核IP,而寒武纪IH8有 4 种可选的配置1T、2T、4T、8T OPS@1GHz,麒麟980应该是4TOPS的版本。而麒麟990系列的NPU并未公布具体的OPS数据,不过其采用了全新的达芬奇架构以及两个大核+一个小核的配置,性能应该更强。
0 r7 ]+ f% i, T$ M7 z9 X% ]; a6 c
* S0 z F* ~. k0 V2 p3 j8 k/ q. N& J2 l( X9 B) s9 r8 l/ w8 w. ^
在单位面积的算力方面,根据芯智讯此前的估算,麒麟970的NPU的单位面积性能大概是1.48 TOPs/mm²,而麒麟980和990没有相应数据可以参考。而根据TechInsights的拆解,苹果A12的NPU内核的面积为5.79mm²,也就是说苹果A12的NPU的单位面积算力约为0.86TOPS/mm²。
1 j! K3 d3 l% w1 l/ o% e2 _ u* L; C8 z7 d$ [% D9 {; m
3 {- O, Y1 |. A: W: ` k* R
在每瓦算力方面,华为公布的资料显示,麒麟810的每瓦算力可以达到6TOPS。苹果的NPU未有相应数据。寒武纪新的NPU内核1M在7nm下每瓦性能为5TOPS。
5 _8 x3 x0 ? D! O- G
& R% M( {) T8 ]0 I" [' ^. G; b$ O/ Y+ G% Q; J/ A) u' x
从上面的数据对比来看,Ethos-N77的AI性能与苹果A12和麒麟980的NPU相当,相比麒麟990系列的NPU性能可能要弱一些。在单位面积算力方面,远高于苹果A12和麒麟970的NPU。在每瓦算力方面,也是远高于苹果A12的NPU,略低于麒麟810。综合来看,Arm Ethos-N77各方面都还是比较出色的,达到了目前旗舰级NPU的水准。
' A7 [4 }" L; q; ^9 B9 T. E8 p% A# G4 M2 y
" P& T( v; j+ a9 q e5 [需要指出的是,4 TOPS的性能是单个Ethos-N77核心在1GHz主频下的性能,如果配置双核的话,那么性能无疑将进一步提升,当然功耗和面积会进一步提升。
. W3 J4 M5 }( @7 I* y) P; N+ }/ z& Q7 x, O& O! T! b. s
/ M- ]8 j2 \6 n" ^3 V
Arm此前就表示,Ethos系列IP是具有高可扩展性、兼容性和可编程的,可以提供计算性能最低从2 GOPS到超过70 TOPS的产品。
/ H; t/ n5 u) q
. _4 o; r* G& U/ a; l6 b6 }$ Z4 Z: k
另外,Arm还推出了针对主流市场的Ethos-N57,内置了512KB SRAM,在1GHz主频下,算力最高可达2TOPS;而针对低端市场的Ethos-N37,是为了提供面积最小的ML推论处理器(小于1mm²)而设计,其同样也内置了512KB SRAM,在1GHz主频下,算力可达1TOPS。. u7 e$ V0 R4 x6 f5 s, `
" T: e0 j5 F+ C" Y
- ~- ?/ r6 z( |' K( r
Arm表示,Ethos-N57和Ethos-N37针对Int8与Int16数据类型的支持性进行了优化,通过如创新的Winograd技术的落地,使性能比同类NPU提升超过200%,并且配备了先进的数据管理技术,以减少数据的移动与相关的耗电,在ML在性能与成本、面积、带宽与电池寿命之间达成了比较好的平衡。4 z" {* S* k- j; u
8 o: k+ C% e" y. H" T( g p4 W: s
' J8 q7 F* [) m, v/ T: f$ _% I据芯智讯了解,除了移动市场之外,Arm的Ethos系列IP未来也将会开始进入物联网、工业、汽车、网络以及服务器市场。
$ n- y& m2 [3 X6 B* G5 A, L6 C1 n, q4 t; [8 _
+ i7 o$ z1 f* P
开源的AI开发框架Arm NN+ b$ w0 A- }1 G6 p; {) b5 |
7 t5 h! _- A } Q! q1 f
& `7 ? @& k" v% k7 L! O0 h0 p我们都知道,此前高通骁龙845/855系列都并未内置专门的NPU内核,但是其仍然提供了较高的AI能力,而这一切得益于其神经网络引擎Neural Processing Engine的助力。即采用更为弹性的异构的机器学习架构,在通用平台内做内核优化,使得AI计算合理的分布在CPU、GPU、DSP等每个单元上,从而可以针对不同移动终端提供弹性调用各个处理单元来进行AI计算。7 ^/ a0 s0 U! x% d3 Y
9 E0 y, N' m1 ~" Y7 t( ?' N8 \1 T/ D8 H# |
而Arm此次在发布Ethos系列NPU IP的同时,也推出了开源AI开发框架Arm NN,强化异构的AI计算,进一步提升整体的AI性能。( p- I+ y2 g* J) A3 _" J& n% F2 w
5 x- U' V r" g5 }
r$ ?$ }+ m/ V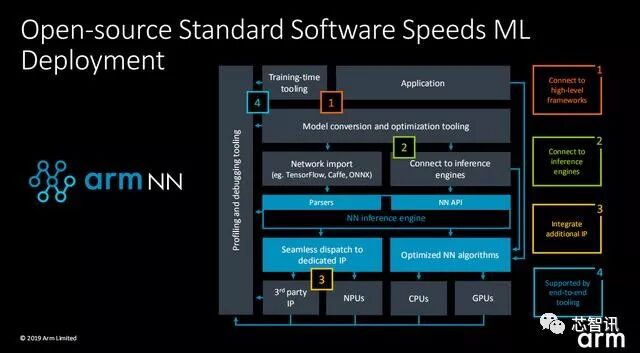
( l: O5 N4 j+ T6 v- n4 i |' v
2 ~" J$ p: H! b3 e' I/ Y
7 S" q# `/ r4 J3 Q1 t' U! o% i据介绍,Arm NN是属于偏底层的架构,而且在其基础之上,可以支持其他的更高层级第三方的NN框架,并提供完整工具链,可实现在AI计算上对于Arm CPU/GPU/NPU内核的合理调用,实现更高效的异构的AI计算。) B9 h$ A# }+ u- [$ Y) N I$ t' I
8 x# P0 x7 A; k V; R
7 X+ R- Z; u) c& ?) eArm表示,由于不同的SoC对于AI的加速方法是不一样的,因此第三方应用及开发者要用到片上系统的加速能力是比较困难的。而开源的Arm NN的推出,将降低开发者调用Arm内核的难度,进一步提升开发人员的体验。
8 i, z4 m. x# w i4 p7 ]0 ~) a# G1 z$ w! N, x: t |! x
3 K5 H1 v: P7 K+ Z: N6 s
+ z9 P% A1 S# _ @- }4 G6 ` i" ]( y3 K1 b
9 |! z/ ?3 f/ @) e$ L& n4 i. ^此外,为了推进基于Arm NN的内容创建和开发,Arm还与Unity(Unity最目前主要的3D引擎,50%的3D游戏,75%的VR内容都是基于Unity引擎开发)达成合作,进一步优化Unity引擎,使得基于Unity的开发者能够更容易的访问和更高效的利用Arm的内核,在Arm CPU/GPU/NPU之间获得更好的性能。可以实现一次开发,即可获得Arm全系列的内核的支持(即可支持众多基于Arm不同类型的内核的SoC),无需再重新编译。* |9 E& q0 Q( w% Y( ^; l
" o( a% i) k3 Q4 \% w2 x
3 Z9 ]# b1 y- Y; D, o. F* \$ U3 rMali G57 GPU:为主流市场带来智能与沉浸式体验
- R7 U1 L) Z; g$ x; j1 {$ ?6 L; w0 c8 f) [
8 B! ?0 W- V3 M) t今年6月,Arm针对高端市场推出了首款基于全新Valhall架构的GPU——Mali-G77。今天,Arm针对游戏市场推出了第二款基于Valhall架构的高性能、高能效的GPU内核——Mali-G57。(Vahall架构进一步提升了并行执行的能力,同时在代码上也做了尽量的简化,从编译角度来讲也更加友好。)4 J. H+ p6 ]0 w6 ^: o' i- Z
5 k4 G4 v, l- ]( s4 `) x$ r
& h8 s7 _6 t9 R, L+ m0 d& v: r& Z1 p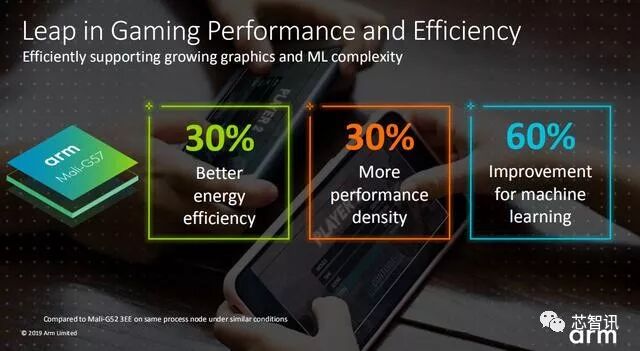
6 _( S& [0 V/ c+ } V# l( e8 m m) I' @
! E* f' O- |2 m7 _
据介绍,Mali-G57的性能相比上一代的Mali-G52在能效上提升了30%,性能密度提升了30%,机器学习性能提升了60%。并且Mali-G57还加入了针对虚拟现实(VR)提供注视点渲染支持,再加上机器学习性能的提升,可以支持更复杂的XR实境应用。而且,Mali-G57还支持1-6个核心的配置,可以满足不同市场定位的智能手机的需求。: U' k% l6 a- Y
) }0 J# }0 z( b2 ~' N3 h% d: S
6 b! @8 ~: W; RArm表示,Mali-G57可以将优质的智能与沉浸式体验带到主流市场,包括高保真游戏、媲美电玩主机的移动设备图型效果、DTV的4K/8K用户接口,以及更为复杂的虚拟现实和增强现实的负荷。. c7 [4 F5 c" @) _1 G
Y2 g( k7 v. v1 Y
+ j, |+ w- b! a! b4 o- H
Mali-D37:Arm单位面积效率最高的DPU
5 M8 t5 G9 p7 l8 q' s! t4 \
6 g0 Y- t ~& C. X. S9 J6 Y8 e$ B* @- Q; g6 B: U# d6 ^! d
在今天的技术论坛上,Arm还推出了目前单位面积最高效的显示处理器Mali-D37。* T K; g' g3 y% B' Z
+ e, h: {! X& j( c: M6 ~
: t) f) O% u4 q) M
. G) e3 }) p4 N$ n. |' t3 C0 I
; P) b: k5 q1 |: Z, y8 l
- h9 o; ^+ M& l' I& s据介绍,Mali-D37是Arm第一个面向主流市场的基于Komeda架构DPU,拥有极高的单位面积效率,在支持全高清(Full HD)与2K分辨率的组态下,16nm制程的面积将小于1mm²。+ Y) H0 [# L8 e5 l, L1 g" E
. j) u& T; Y P+ s* I4 L
0 U% d0 b1 U) @6 g- J& ] g
在性能方面,Mali-D37保留了高阶的Mali-D71关键的显示功能,包括与Assertive Display 5结合使用后,可混合显示高动态对比(HDR)与标准动态对比(SDR)的合成内容。另外,Mali-D37其通过将部分GPU核心显示的工作负载卸载到Mali-D37来工作,以减少GPU的工作以及对于内存的访问,使得系统的功耗可以降低30%。
4 r5 {6 U( J! D& h8 @ d- }/ j0 S1 _, y" e) w2 A' K) L, F
! p$ p5 l0 \, x% B2 E) F! gArm表示,Mali-D37可以支持入门级智能手机、平板电脑等成本较低的设备,获得2K级别的视觉效果与性能支持。
+ J1 z" W, W5 w( A1 @+ A' X; l! \ s) S/ w9 \1 j
& a" W: \5 t8 @2 K7 OArm的通用型NPU能否获得成功?
* M6 Z3 R$ g% O9 X6 @
: B2 X; W T' [ Y S% n2 @$ t# _( E& o, B
从目前的市场趋势来看,AI芯片正越来越向专用化的方向发展,越来越多的算法厂商也都纷纷基于自身的算法推出了自己的AI芯片。同样,正如前面我们所提到的,目前华为、苹果、高通、三星、展锐等众多的手机芯片厂商也都有推出自己的NPU内核。那么Arm的“通用型”的Ethos NPU IP真的有市场吗?
- y" R. b% V! Y$ R S3 n
+ j; U) b# Z+ t9 X: ?; B/ t4 h# L9 K7 U( V" F! D% l9 q
对此,Arm市场营销副总裁Ian Smythe表示,Arm的Ethos NPU IP并不是孤立存在的,其主要的优势在于,在其本身提供出色的AI性能的同时,可以更好与Arm的CPU、GPU进行协同,以实现异构的AI计算,从而进一步提升整个系统层级的AI性能、降低功耗。而且,目前AI市场还是在初期,很多的AI算法仍在快速迭代,选择“通用型”的NPU是比较安全的做法。
# H) P3 z, e, c* t5 {
) R" A4 D q" p) P3 h' W6 s y3 I0 B& H2 P
n) u+ H* M* ?; F5 m v( ]9 x! I" n" w q/ F% i- Z
+ @- V# x2 A% P1 r
在采访当中,Ian Smythe向芯智讯确认,Arm的Ethos NPU IP也可被集成于比如RISC-V等其他架构的SoC当中,但是Ian Smythe也强调,这样并不能发挥出Ethos NPU与其它非Arm CPU/GPU在AI计算上的协同优势。/ n" K9 }- b3 M
* c+ `0 X$ I5 Z8 E% m7 B [
9 Q$ k/ N, F+ w8 K. q9 u. u# s另外,Arm的Ethos NPU IP还实现了对于高中低阶的全面覆盖,但是目前众多的芯片厂商主要还是在其高端SoC当中集成了NPU,而随着AI计算向边缘侧部署的趋势,未来市场对于NPU的需求也将会越来越大。Ethos NPU IP的推出,将可帮助芯片设计厂商更简单、更低成本的获得不同档位的NPU内核的支持。
7 Z! q, U* G5 n/ @' a
7 {: Y/ c1 G0 x& b
1 N7 G! W1 C" |" E* z0 l另一方面,目前的Android应用生态基本都是基于Arm架构的处理器,因此,如果采用Arm的Ethos NPU IP,结合开源的Arm NN框架,应用开发者将可以更简单、高效的调用Arm的CPU/GPU/NPU内核,可以为用户带来更为出色的AI体验。而且,可以实现一次开发,即可获得Arm全系列的内核的支持(这也意味着,可支持众多基于Arm不同类型的内核的SoC),无需再重新编译。而对于其他的芯片厂商的NPU来说,开发者要想实现灵活高效的调用NPU,充分发挥其AI性能,则需要针对性的进行优化,而且还需要其提供相应的权限和工具。即便是开发者开发应用实现对于A厂商的NPU调用,同样的应用要想实现对于B厂商NPU的调用,可能需要重新进行编译。显然,对于应用开发者来说,Arm的NPU所具备的生态优势无疑是其他厂商所无法比拟的。
% A" L: T9 l. x
3 T2 l, `7 k9 R/ b/ M) c+ A- i( _2 j& W, Z* T$ l, f- O9 v5 g( h
最后,Ian Smythe强调,Arm对于AI性能的提升是多维度的,一方面会持续推出更高性能的NPU IP,同时也在不断提升Arm CPU/GPU的AI性能。( e3 h4 q* I7 ^( m P$ B7 Q
D6 |' F) V9 r8 M( H; U6 {% X1 Q' ?6 v7 Q- V7 u3 E0 ?3 o& F. ^, ?6 |
- A7 F9 g8 w. L8 A3 Y8 n5 {6 Q+ [ V& S
4 m9 } l5 L' l
值得一提的是,Ian Smythe在演讲当中透露,Arm在下下一代的大核架构Matterhorn当中,加入Matrix Multiple(MatMul),令其ML(机器学习)性能与前代CPU相比提升一倍。
: `) F1 w/ i+ S8 ]! G# W. l. ^+ w4 j' k6 M5 Y5 F" X
& ~, ~ b, z1 M5 c0 U编辑:芯智讯-浪客剑
* Z! c# Y+ m1 B$ F b' J往期精彩文章. b1 h+ S# }) u) A
VR市场迎来第二春:5G+VR云化将成最大推力!! c7 h x; H9 Z
" q( A6 y* k- _4 V) t1 W
2019生物识别论坛成功落幕:这十大看点不容错过! {$ a' m4 p9 r4 W
阿里平头哥正式开源RISC-V架构MCU芯片平台
4 n4 |6 i* `5 b" ^首度杀入3D人脸识别门锁/门禁市场,英特尔为何选择与小钴科技结盟?
' N! |; M4 n) L: r; @) B7 }2 O% _; F6 D" j+ `8 q
展锐再推4G功能机芯片虎贲T117,意义何在?
2 l }4 J8 u4 [& C
- |# f* }6 H2 _' \* P2 l: X历史首次!华为海思4G芯片Balong 711对外销售!* v$ ^0 p! C2 N" C+ R
# T0 g: T6 ]' _8 j' O" C) a1 o+ w2 |
不惧美国打压!华为已获得65份5G商用合同,5G基站发货超40万个!. f, e0 x+ i* B$ m& K& ]
5 f9 @/ d/ `, m: `4 w
巨额债务违约+资金链断裂?手机ODM厂商海派关厂裁员!8 L3 `) d+ R, G+ G" M1 U
" n4 {6 M6 n9 F- d' d( c; z3 m; G; E可穿戴巨头Fitbit宣布撤出中国!
" o. y4 A" b1 `+ u- {* `/ K: m; ^, w; M) J# e4 t
收购Intel基带芯片业务涉嫌违规?苹果遭市监总局启动问询
( K$ b) _2 i9 y9 F: z6 i% g9 Q/ `% Y1 m
$ d- d& s# j( K% N$ R1 r禁令之下,安防巨头海康与大华的应对之策!
$ a1 E: }# m4 J+ z" t ^2 Y. P4 O9 `1 a
为应对RISC-V挑战?Arm CPU引入自定义指令功能!
/ o, m1 f7 w( j! {- t行业交流、合作请加微信:icsmart01
$ @4 ^: [0 U0 D% k5 a芯智讯官方交流群:221807116 2 \. i6 H1 v, ]- S3 @. C
A/ p1 S- @2 C) m$ p' O D来源:http://mp.weixin.qq.com/s?src=11×tamp=1572103805&ver=1936&signature=jeCKwe1UBQzC*Pzs8GoY9TZBvEs1rdMAvR4c22h3Cpdg-qQ*TOrpE2uZ4YvRMx7pQMFu5Q-as9lkvJgPIZqWm1WA-*ncmgAC2Ls6p79VafFsjOW9cM78m6hG7c-lzR2Q&new=1, G2 }- |/ L' v5 G% z8 H% H, r9 u
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册

×
|
 |手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图
|手机版|小黑屋|梦想之都-俊月星空
( 粤ICP备18056059号 )|网站地图

 发表于 2019-10-27 00:33:22
发表于 2019-10-27 00:33:22
